
大家好,这里是Bo2SS~真快,毕业过去一年了,公司又注入了新鲜的血液。部门里有一个大前端新人培训,自己斗胆报了名,做一个HTTP相关知识的分享。其实之前自己没有系统地学习过HTTP,所以提前了2个月准备这次分享。上周分享完后,据问卷反馈全员五星🌟好评,就在这里记录一下吧~
前言
如题,今天要聊的是网络通信中HTTP和HTTPS的那些事儿。
Q:为什么要分享这个主题?
-
🫡 生活中常见。HTTP在整个互联网是非常常见的,比如我们看剧、刷短视频、面向Google编程,都会用到它。作为研发,我们有义务深入了解一下。
-
🤔 工作中常见。在我们工作中其实经常会遇到相关问题,比如在前后端接口联调的时候,如果遇到了预期之外的情况,我们首先要去关注的,就是HTTP请求里的一些信息。我们应该熟悉它的结构和一些规范。
-
📖 思想可借鉴。HTTP它发展了30多年,3个大版本,它的很多设计思路是值得我们在开发中去借鉴的。
Q:参考了哪些资料?
这次分享前我做了很多准备工作,主要参考的有:
-
极客时间上的《透视 HTTP 协议》课程。这个系列我可能也就听了十吧遍吧,如果大家想深入了解更多的细节,可以去看看。作者还提供了可以实战学习的仓库chronolaw/http_study,通过它你可以很方便地搭建一个Web服务器,然后通过浏览器去访问里面的资源来理解HTTP。
-
小林Coding。这是我关注比较久的一个公众号,里面有很多关于计算机基础的图解系列文章,现在也有了小林Coding网站版。
-
Bo2SS。这是我自己的公众号,就在这里啦👋。之前写过2篇HTTPS相关的文章:
此外,文中也引用了一些第三方的图片,就没有一一列举来源了,如有不当之处,欢迎联系。
Q:这次分享的目标?
-
🔍 快速定位HTTP问题。刚刚说到了我们在前后端联调的时候,可能会经常遇到结果不符合预期的情况,我们应该首先能够通过状态码去快速定位,这个问题是后端的还是前端的。
-
🥣 熟悉HTTP报文里的常见头字段。熟悉常见的头字段后,我们不仅可以掌握HTTP的基本功能,还可以学到很多HTTP的设计思想。这个报文在哪里可以看到呢?各端一般都会有抓包工具来查看。
-
🔐了解基本的加密知识。互联网时代,用户隐私、业务保密都是非常重要的。
🏁终极目标:看完这篇文章,你将拥有自行深入学习HTTP的能力了,比如通过WireShark、Chrome、Telnet工具,甚至可以去看RFC文档,里面几乎包含了所有网络相关的重要资料。
➕一些资料:各工具的使用指南(WireShark、Chrome、Telnet),RFC文档汇总。
Q:这次要分享哪些内容?
也就是这次分享的大纲:
简单来说,今天要聊的就是HTTP和HTTPS是什么,然后它们怎么发展的。
好,下面进入正题:
什么是HTTP?
HTTP是什么,又不是什么?
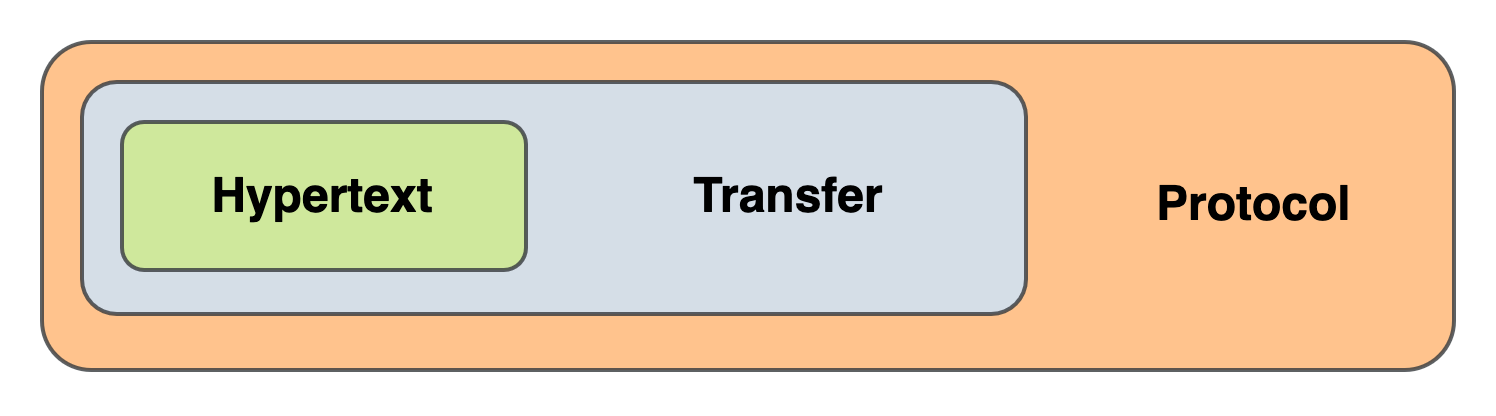
HTTP的全称是Hypertext Transfer Protocol,也就是超文本、传输、协议。我们从后往前解释~
-
协议。什么是协议,我们可以联想我们的租房协议、三方协议,其实都是一样的含义,协议的“协”,代表有两个以上的参与方,协议的“议”呢,代表约定和规范,约定你可以做什么、不能做什么。
-
传输。然后是传输,我们可以联想快递,专门在两点之间传输,其关键有两点。第一点是双向性,我们可以寄快递,也可以收快递;第二点是传输过程可以有中转,比如我们寄快递,会经过快递小哥、快递公司、物流仓库等,最后才会到达收件方,同时这些中间者也都遵守协议。
-
超文本。最后关于超文本,顾名思义就是超越了普通文本的文本。这里我想问大家一个问题,超文本除了文字、图片、音频、视频格式,还有一个最关键的格式,是什么?对了,就是超链接。超链接能够让我们从一个“超文本”跳跃到另一个“超文本”,让我们的文本从以前的线性结构,变成了非线性的网状结构。
一句话总结就是:“HTTP是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范”。
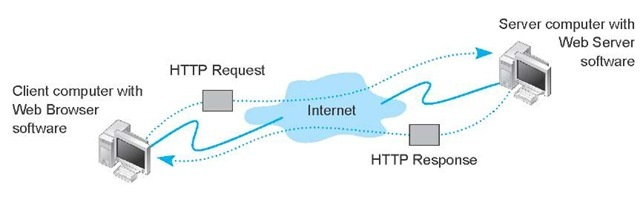
这张图是我们基本的HTTP通信过程中的参与者们。从这张图,我们可以捋清HTTP它不是什么,从而对HTTP有一个更清晰的认识。
-
HTTP不是实体,比如左边的Web浏览器(发送方),右边的Web服务器(接收方)。
-
HTTP不是互联网,HTTP传输的超文本资源是互联网资源中的一部分。
-
HTTP不是一门编程语言,但是HTTP支持各种编程语言来实现。
-
HTTP不是HTML,HTTP可以传输HTML,HTML是超文本的常见格式。
-
HTTP不是一个孤立的协议。通常在HTTP的下方,会有一些底层协议支持,比如TCP、IP、DNS等等;在HTTP的上方,也有一些依赖于HTTP的协议,比如WebSocket、HTTPDNS等等。这些协议相互交织,构成了一个协议网,而HTTP则处于中心地位。
HTTP世界全览
我们再对HTTP世界的全貌进行一下浏览,主要分为应用相关和理论相关。有了对HTTP通信链路更宏观的认识,我们在定位问题的时候,能够更清楚问题可能是由哪个环节导致的。
HTTP相关应用
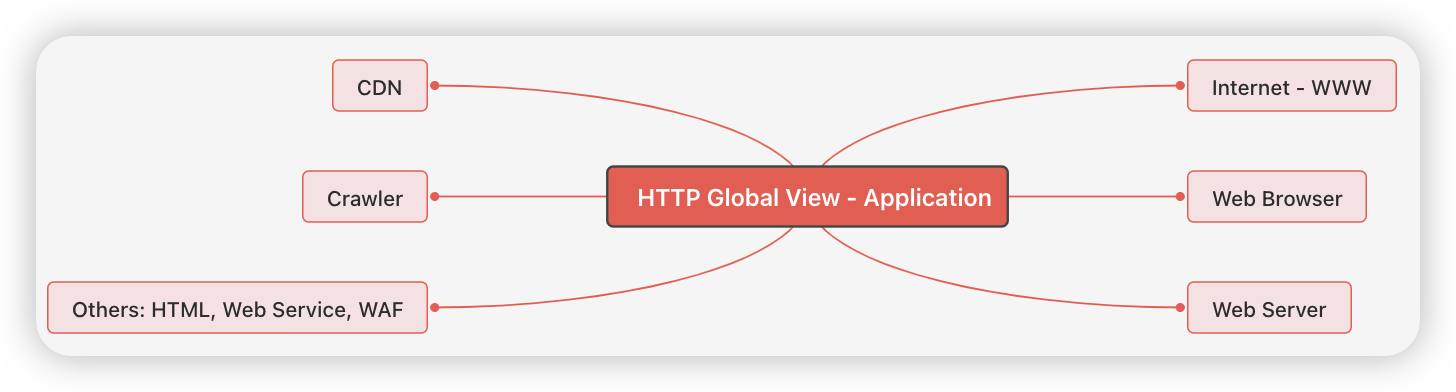
我们从右往左看:
-
Internet - WWW:Internet就是互联网,里面存储着各种信息资源。WWW是互联网的一个子集,简称万维网,它基于HTTP,所以存储的都是超文本资源,这些资源在互联网中的占比大约在90%。
-
Web Browser:Web浏览器,是HTTP通信过程中的请求方,并可以显示请求到的资源。
-
Web Server:Web服务器,是HTTP通信过程中的响应方,由它来管理网络资源。一般会将它分为硬件和软件,硬件指物理服务器、云服务器之类的机器,软件指Nginx、Apache之类的应用程序。
-
CDN:Content Delivery Network,也就是内容分发网络。前面说到HTTP的传输过程可以有中转,这里CDN的定位就是中转方,起到网络代理的作用。它可以缓存服务器的资源,加快网络响应,还可以提供负载均衡、安全防护等能力。
-
Crawler:就是爬虫。和Web浏览器类似,它也可以理解为是一种用户代理,一般是给各大搜索引擎自动抓取数据、存入数据库用的。
-
Others: 其它还有HTML、Web服务、WAF。Web服务可以理解为运行在Web服务器上的具体服务或者服务开发规范。WAF的全称是网络应用防火墙,它其实也是一种代理。
HTTP相关理论
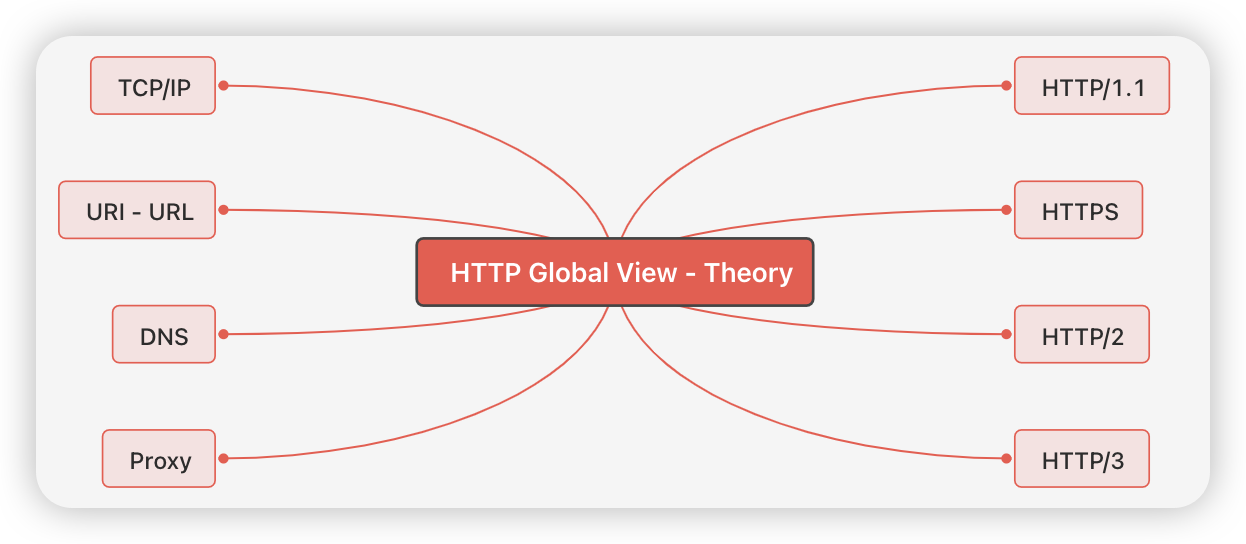
同样从右往左看,右边的HTTP/1.1、HTTPS、HTTP/2、HTTP/3就是今天我们要聊的主要协议,左边:
- TCP/IP:它代表的其实是一个协议栈,里面包含了很多网络通信协议。
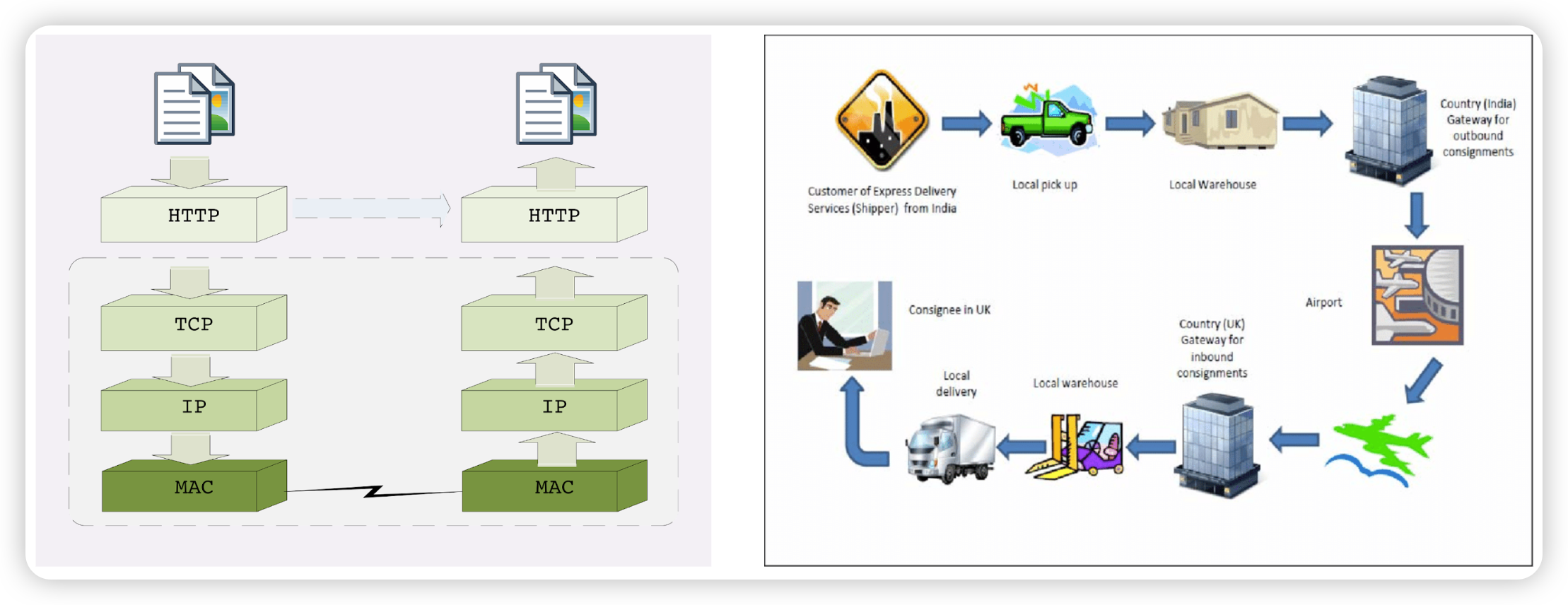
这里我们把基于TCP/IP的HTTP通信过程与快递运输又做一个类比:
1)超文本 => MAC:左图中左边这一列,要传输的超文本从应用层一直到链接层,每经过一层都会被加上对应的头,比如HTTP头、TCP头、IP头、MAC头,这就像快递的打包过程;
2)MAC => 超文本:左图中右边这一列,被传输的数据每经过一层则都会被去除一个头,这就像快递的拆包过程。
- URI - URL:URI(I - Identifier)是统一资源标识符,它又分为URL和URN两种形式,但因为后者在互联网世界并不常用,所以URI一般指的就是URL。
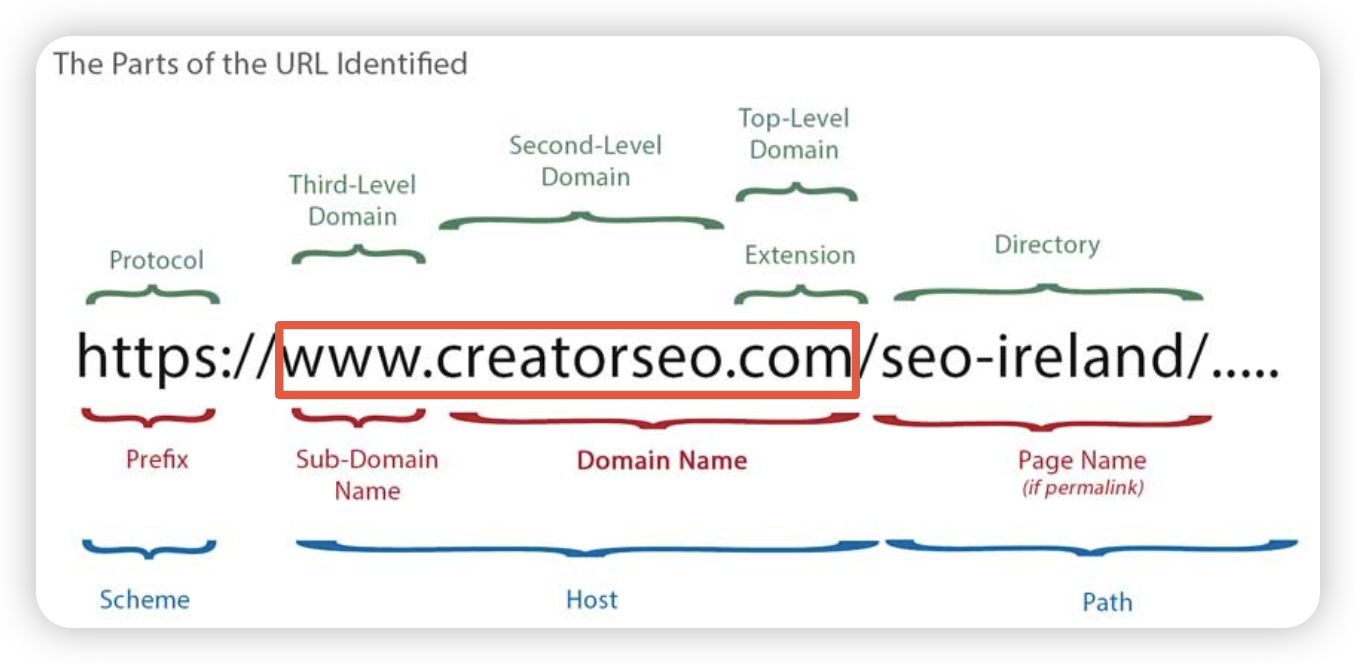
1)URL(L - Locator):我们浏览器上方的地址就是URL。

它的基本组成如上图,我们可以先关注红框部分:
-
scheme:最左边的scheme代表协议,如http、https、ftp等等。注意这里协议后面紧跟的
://符号是固定的、必须的。 -
host:中间host是主机名,也叫域名,待会讲DNS的时候再细说。
-
path:最后边的path代表资源路径。
Q:这里有一个问题,图中示例URL的域名是www.creatorseo.com/吗?
答案是否定的,最后面的斜杠/属于path,它代表的是所访问主机的根目录,因为早期互联网上的计算机大多是UNIX系统,所以这里的路径格式是采用的是UNIX上的文件路径风格。
下面还有一张图,这张图是URL的完整格式。

比上图还多了三个组成:
-
user:passwd@:我们可以在URL里就填上用户密码信息,但因为安全原因已经不推荐使用它了。
-
?query:这个部分可以附加一些对资源的额外要求,以
?开始,由多个键值对k=v组成,每个键值对用&连接。 -
#fragment:它代表一个片段标识,我们可以理解为资源内的一个锚,它是给客户端使用的,不会发送给服务器。平时我们在看一些博客时(如阅读原文跳转到我的博客网页),点击悬浮目录中的某个标题做跳转,就是用的这个部分。
💡 这里还有两个小提醒~一个是host后面还可以通过:port指定端口。另一个就是一般聊到URL时,还会聊到escape转义和encode编码两个概念,因为如果没有它们,服务器可能就无法正确地处理URL。试着想一想如果path里也有?符号,服务器该怎么解析出query的起始位置呢?
-
escape - 转义:针对特殊字符,我们一般会做转义,直接将其转换成ASCII码的十六进制后再加一个
%前缀,比如SPACE对应%20,?对应%3F; -
encode - 编码:针对汉字等其它语言,我们一般会先进行UTF-8编码,再转义。如果你不信,可以试试把包含中文的URL复制粘贴到微信中(如阅读原文跳转到我的博客网页)。
2)URN(N - Name):下面再回到URI的第二种形式URN,它是通过命名空间加具体标识符的形式来标记资源,如urn:<NAMESPACE-IDENTIFIER>:<NAMESPACE-SPECIFIC-STRING>。它在我们上网时不常用,但如果你去买书,可能会发现每本书的条形码位置有一串字符,如ISBN xxx-x-xx-xxxx,这其实就是URN的一种用法。

- DNS:全称Domain Name System,即域名系统,它是用来做域名解析的应用层协议,也就是将域名转换为IP地址。
我们先来看看域名的结构,还是这张图,这里红框部分就是域名,它是一个有层次的结构,用.分隔,越靠右边,层级越高。如从右到左,分别为顶级域名、二级域名、三级域名等等。
我们再来看看DNS的类型和DNS解析域名的步骤,如下图:
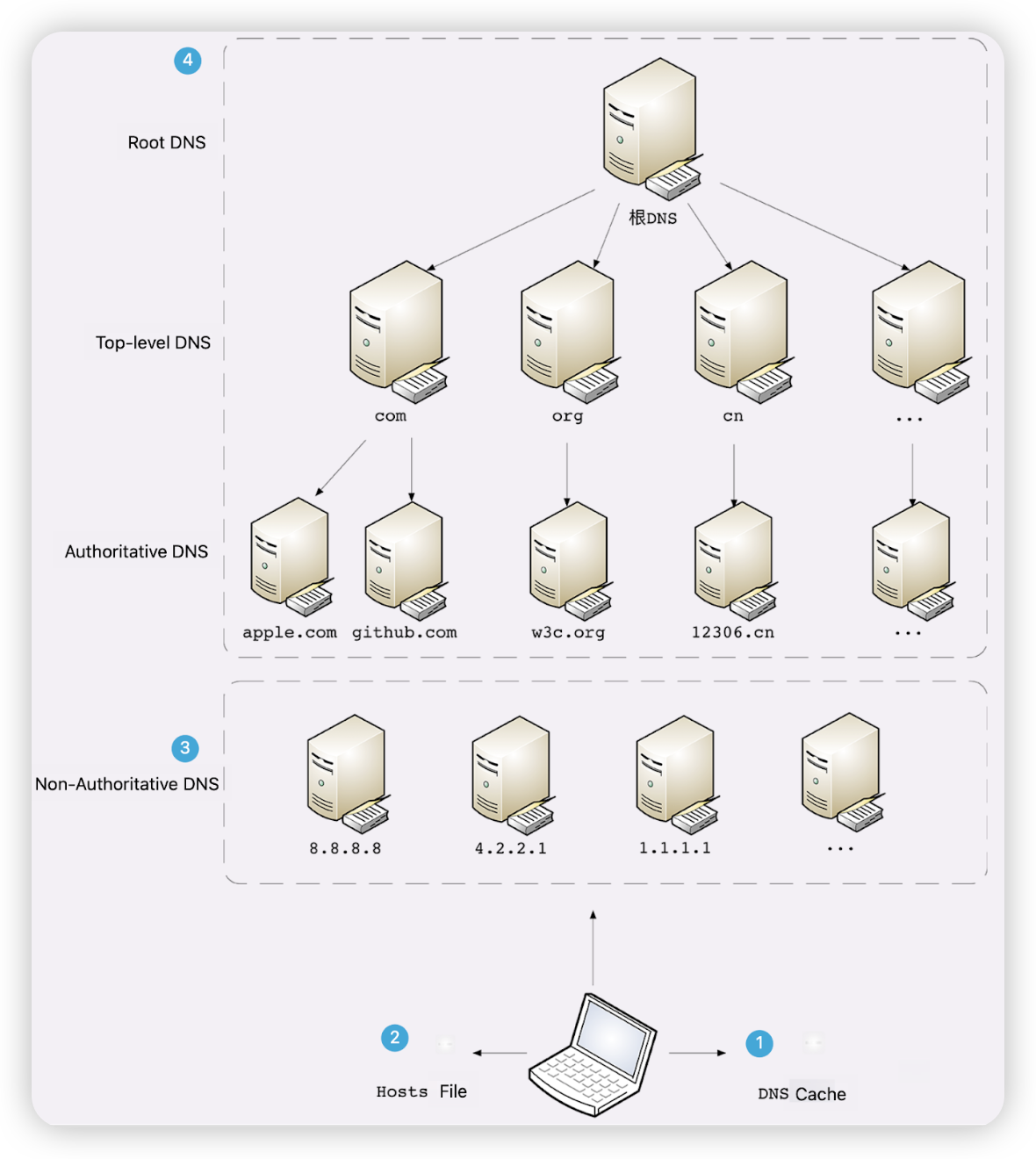
1)DNS类型。DNS分为根DNS、顶级DNS、权威DNS和非权威DNS。根DNS共有13组,遍布全球,它可以根据请求的顶级域名将DNS解析指定给下面对应的顶级DNS。顶级DNS又根据二级域名指定权威DNS,直到解析出域名对应的IP。而一些大公司还会自建DNS,又叫非权威DNS,它们的分布更广,比较知名的有Google的8.8.8.8,Microsoft的4.2.2.1,还有CloudFlare的1.1.1.1等等。
2)DNS解析域名步骤。实际的解析过程分为4步:系统首先会找DNS缓存,可能是浏览器里的,也可能是系统里的;如果找不到,再去查看hosts文件,里面有我们自定义的域名-IP对应规则,Mac下的hosts文件路径为/etc/hosts;如果匹配不到,再去问非权威DNS,一般默认是走我们网络运营商指定的;如果还是没解析出来,就要走根DNS的解析流程喽~
💡 这里还有一些域名解析相关的常用命令(dig、host、nslookup),如果你感兴趣,可以去终端试一试~
1. DNS addressing process: dig www.baidu.com +trace @8.8.8.8
2. domain name <=> IP: host www.baidu.com
3. domain => IP: nslookup www.baidu.com
如果你知道用WireShark,还可以通过filter: port 53过滤出DNS解析相关的抓包。
- Proxy:就是代理。代理一般分为正向代理和反向代理,正向代理靠近客户端,反向代理靠近服务端。刚刚我们提到的CDN属于反向代理,而我们访问外网用的VPN就属于正向代理。
HTTP报文
铺垫了这么多(实际上也是值得的),终于到了HTTP最重要的部分!
所谓HTTP,超文本传输协议,其中最重要的部分其实是最后的协议,里面约定了HTTP报文的格式和用法。
基本格式
我们先来看看HTTP报文的基本格式,它可以简单分为头部和身体两部分:
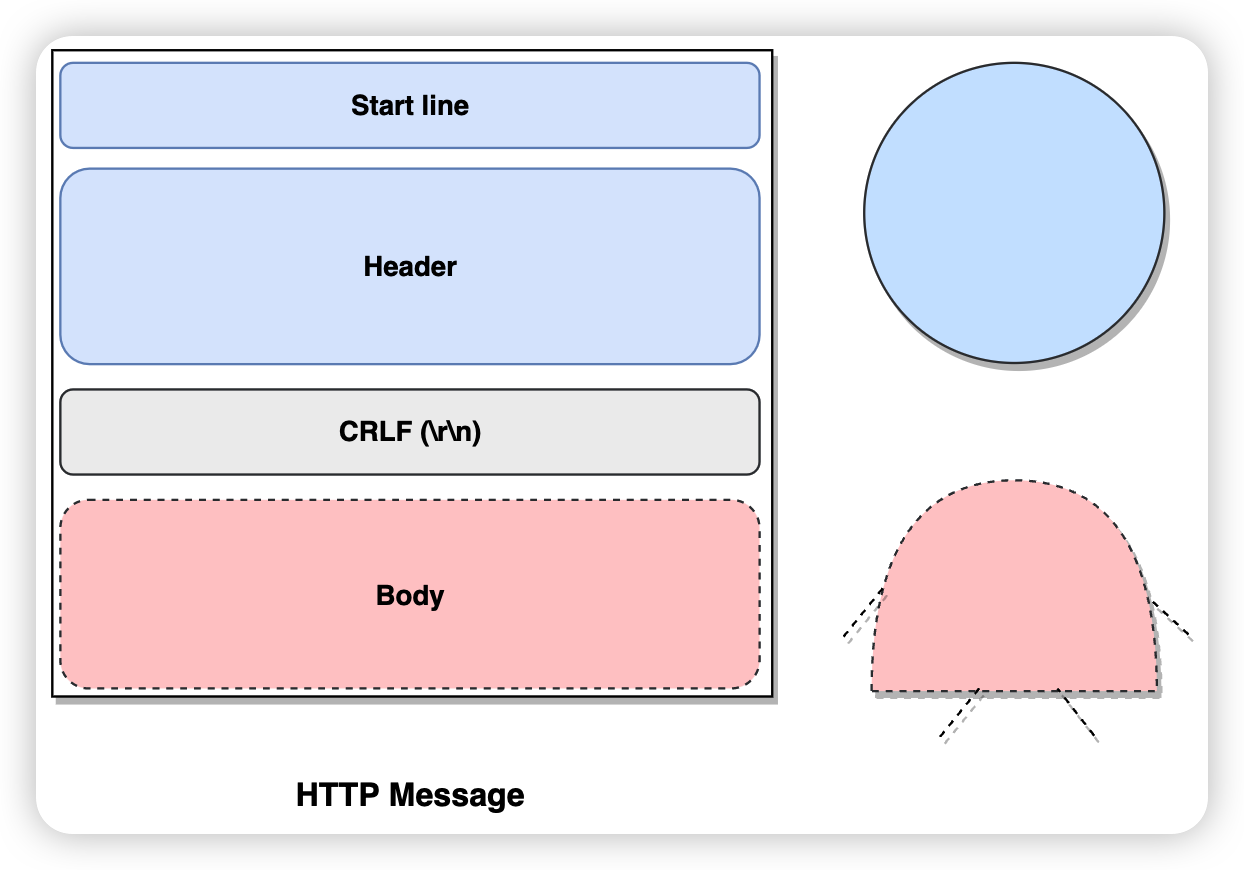
1)头部:一般可以包含起始行部分,也就是头部由Start line和Header组成。下图展示了一次请求中,请求头和返回头的结构:
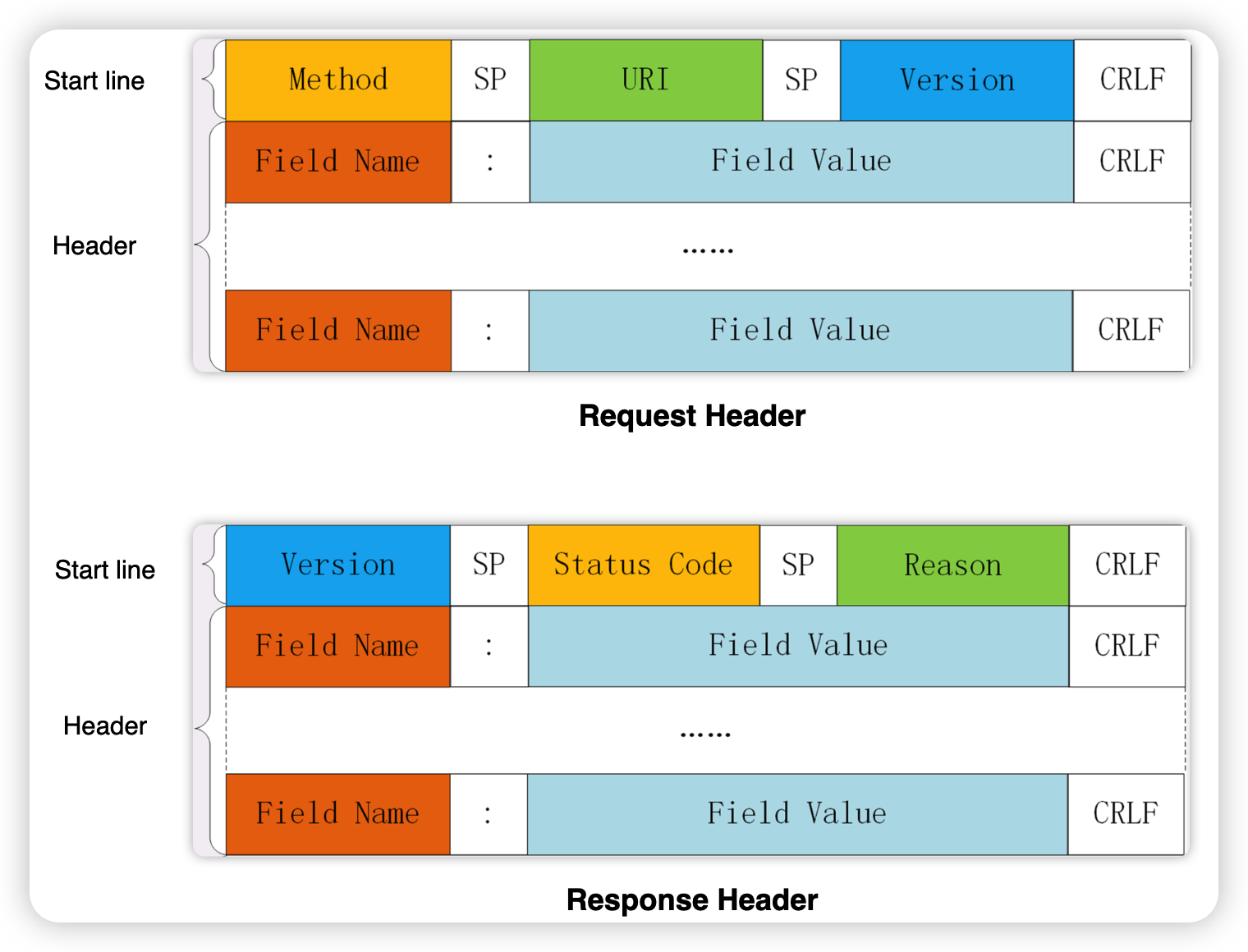
-
请求头
-
Start line由请求方法、URI、HTTP版本、空格间隔符以及最后的换行符组成。
-
Header由一个个的
key:value键值对和最后的换行符组成,注意这里:前不能有多余的空格,不信你用telnet命令试试(Mac上可以使用brew install telnet来安装telnet,并且推荐搭配极客时间提供的实战仓库chronolaw/http_study来用)。
-
-
返回头
-
Start line由HTTP版本、状态码、状态码对应解释、空格间隔符以及最后的换行符组成。
-
Header结构和请求头一样。
-
2)身体:一般根据业务来约定body的具体内容,它是可有可无的。
下面我们再来看看请求行中的请求方法和状态码具体有哪些~
请求方法
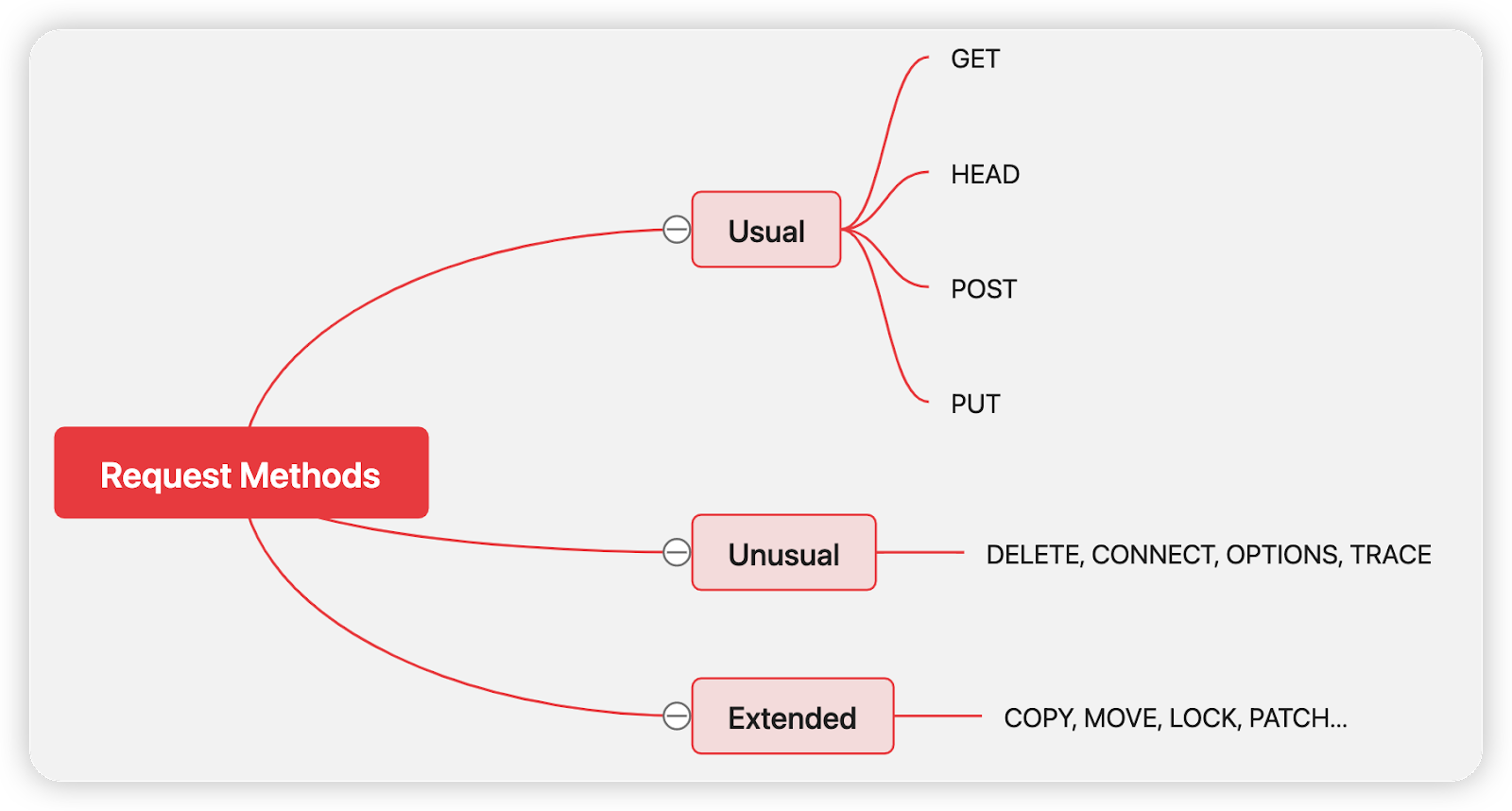
HTTP/1.1里规定了八种请求方法,这里把它们分成了常用和不常用两类,另外还有一类是扩展的请求方法,注意这些方法都必须是大写的形式。
这里主要介绍下常用的请求方法:
-
GET和HEAD,用来获取服务器资源。两者的区别在于HEAD只会获取到头部信息,GET会获取到完整的头部和身体信息。所以如果你只是想确认某个资源存不存在或者只需要头部信息,可以用HEAD请求,从而减少传输量。
-
POST和PUT,用来发送资源给服务器。两者的区别在于前者是在服务器创建资源,类似数据库的CREATE操作,后者是修改服务器的资源,类似UPDATE操作。两者比较类似,实际应用中PUT使用较少。
💡 说到请求方法,一般还会提到安全和幂等两个概念:
-
安全:指的是对服务器资源不会有实质的修改,所以上面提到的GET和HEAD是安全的。
-
幂等:指的是相同的操作执行多次后,结果是否相同,所以上面提到的GET、HEAD和PUT都是幂等的。
返回状态码(5类)
这次到了我们的第一个目标:🔍 通过状态码快速定位HTTP问题。

状态码一般分为5大类:
1xx:提示信息类。一般是一次请求的中间状态,比较少见。
2xx:成功类。这说明请求是符合预期的,也是我们最愿意看到的。
3xx:重定向类。资源发生了变动,需要客户端向另一个域名重发请求。
4xx:客户端错误。看到这个就要想想请求报文是不是填错了。
5xx:服务端错误。看到这个就要找服务端的同学确认问题原因了。
常见的具体状态码可参考下图:
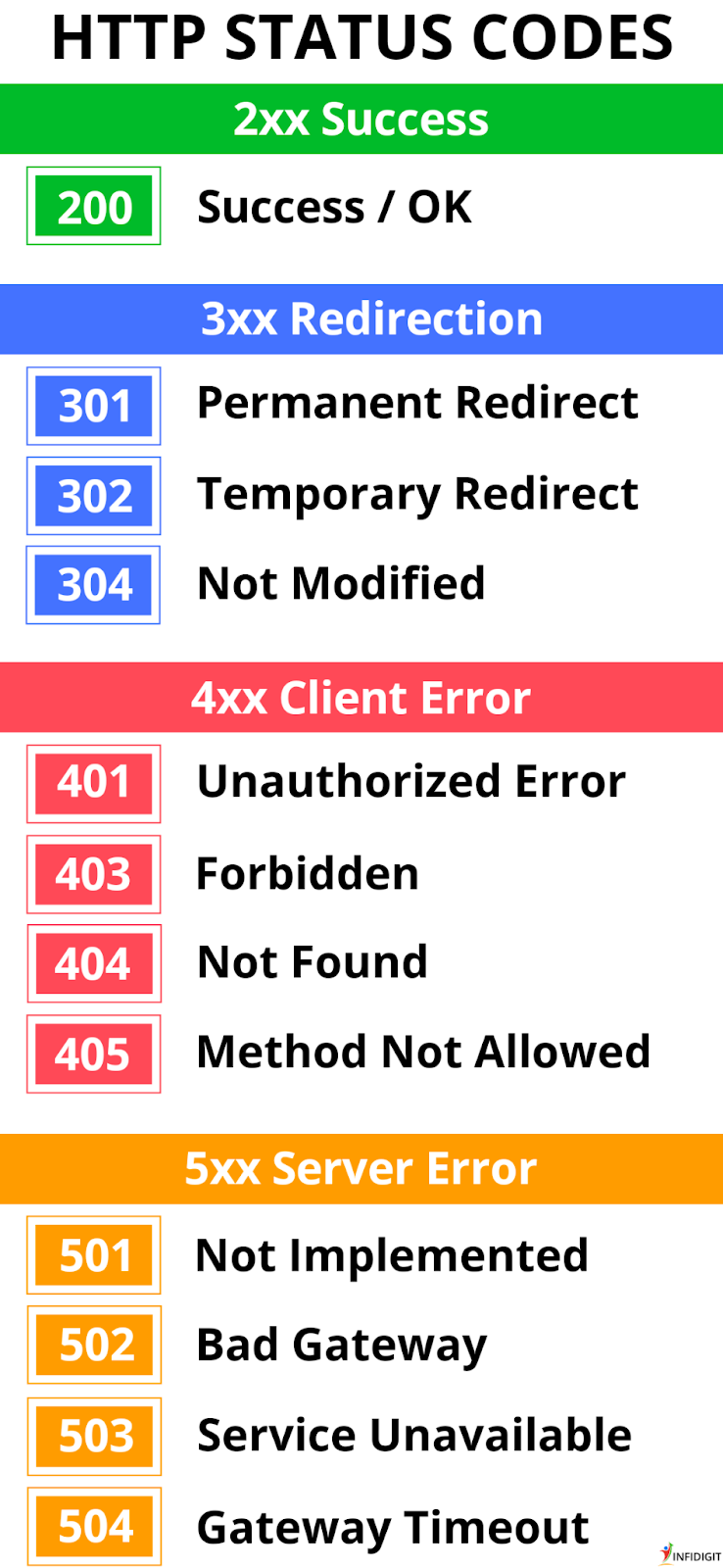
-
301:永久重定向,可以把请求的URL改一下了。
-
302:临时重定向。
-
304:服务器资源没有变,所以重定向到了本地缓存。
-
401:未认证错误,一般与鉴权、登陆相关。
-
403:访问被拒绝,可能访问到了敏感信息。
-
404:资源没找到,可能资源路径写错了,也可能是没有权限访问(错误码是服务端自定义设置的,404一般用于表示资源没找到,但也可以延伸其用途,隐蔽具体原因)。
-
405:请求方法不被允许。
-
502:网关或代理返回的错误码,一般是访问网关或代理背后的服务器出错。
-
503:服务器暂时不可用,请稍后重试。
💡 对于400、500,它们是比较笼统的错误码,有时候是作为兜底错误码返回的,说明发生了未知的错误;有时候是因为服务端不想暴露过多的细节返回的。总之服务端在尽可能遵守公共认知的情况下,是可以自定义状态码的。
常见头字段(8种)
很快,我们又到了本文的第二个目标:🥣 熟悉HTTP报文里的常见头字段。
首先,我们把头字段分为Request、Response、Universal三大类,Universal类里又包含Entity子类。Request类头字段是请求方用的,Response类头字段是响应方用的,Universal类头字段是请求方和响应方都可以用的,Entity类头字段一般是用来描述body属性的。
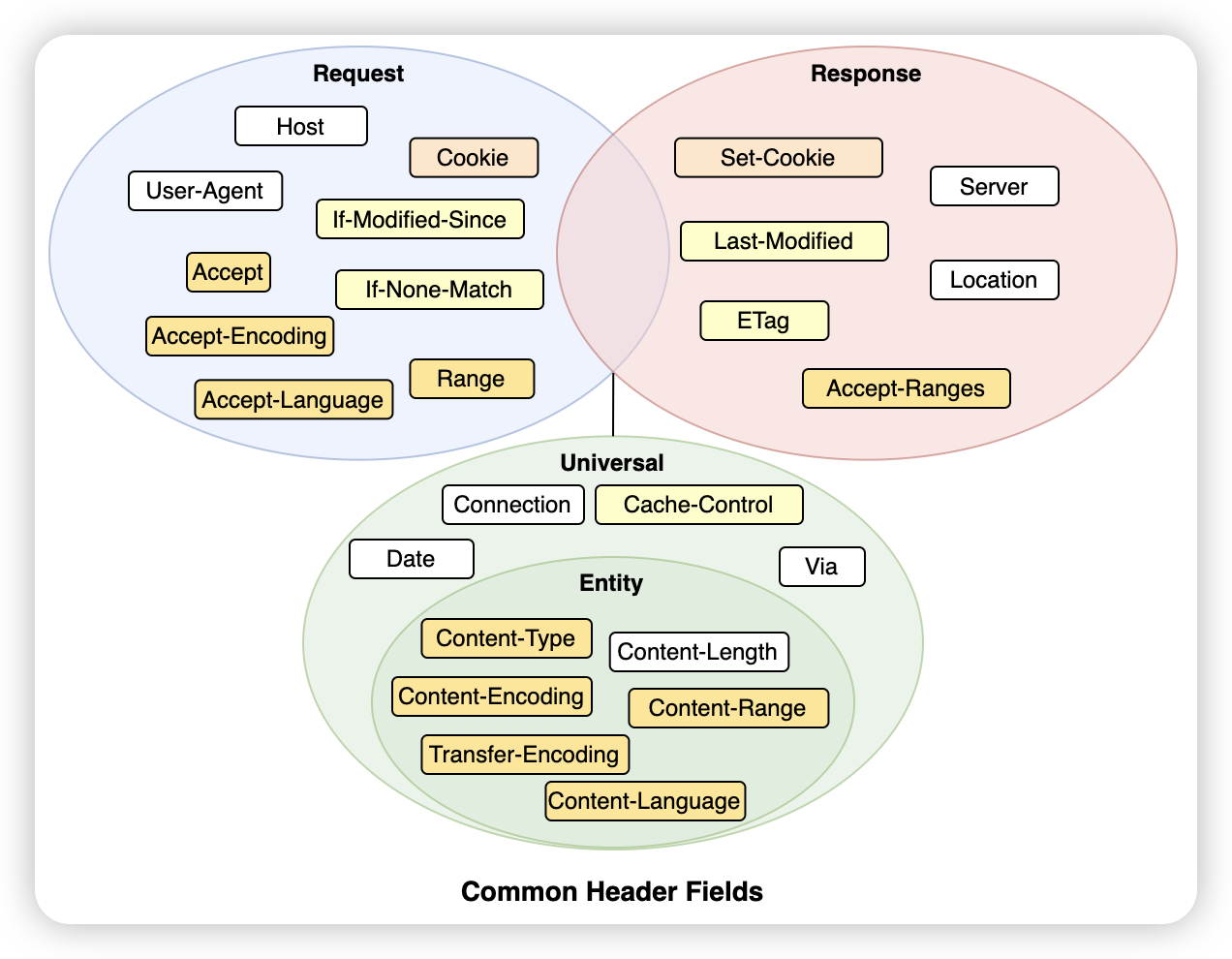
上图列出了常见的头字段们,看着眼花缭乱,别急,我们分功能来解释。补充:填充色相同的头字段们一般是搭配着使用的或者相关的。
下面,我们将头字段们按照功能主要分为8种来解释。
1)Body:body属性相关,可以是描述请求报文中的,也可以是描述响应报文中的。
提到body的类型,我们首先需要了解什么是MIME(Multipurpose Internet Mail Extensions,多用途互联网邮件扩展)类型,它是从电子邮件系统中诞生的,现在也被用来描述body的类型。这里有MIME类型汇总,你点开链接看一下就会觉得它们很眼熟,比如application/json、text/html、text/javascript……它的前半部分是一个大的类别,后半部分是具体的格式。
-
Accept表示的是请求方可以接受的body类型,可能不止一个。 -
Content-Type表示的是实际传输的body类型。
为了减少body的大小,我们一般会对它进行压缩,常见的压缩格式有gzip、deflate和br,它们对text的压缩效果很好。
-
Accept-Encoding表示的是请求方可以支持的压缩格式,可能不止一个。 -
Content-Encoding表示的是传输的body实际采用的压缩格式。
因为上面的压缩方式一般只对文本有较好的压缩率,对于压缩效果不好的图片、音视频等多媒体格式,还有一种方式来解决大文件的问题,那就是分块传输。
Transfer-Encoding: chunked:这表示数据是被分块传输的。
对于视频类型的body,比如我们在b站上看视频,这个视频不可能是一次就请求下来的,我们可以对视频进行分段请求。
-
Accept-Ranges: bytes:我们一般会通过HEAD请求先问问服务端是否支持范围请求,如果支持通过字节范围请求,服务端就会返回这个。 -
Range: bytes=x-y:在服务端支持的情况下,请求方就可以明确要请求第x~y字节的内容。 -
Content-Range: bytes x-y/length:这表示服务端返回的body是第x~y字节的内容,内容总长度为length。
在国际化方面,我们还可以设置对语言的要求。
-
Accept-Language表示的是请求方可以理解的语言,可能不止一个。 -
Content-Language表示的是传输的body实际的语言。
这里还要举一个具体的例子:Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,有两个细节我们要注意:
-
在HTTP规范里,
,的优先级大于;,这和我们一般的编程语言语法相反,所以上面的en;q=0.9是一对。 -
上面的
q是什么?它其实代表一个权重,默认是1,响应方会尽可能使用权重最大的语言返回内容。
2)Connection:长连接相关。
在HTTP/1.1之前,客户端每次和服务端通信都需要重新建立连接,如果频繁通信,就会不断地重复建立和关闭TCP连接,如下图左边所示,即短连接:
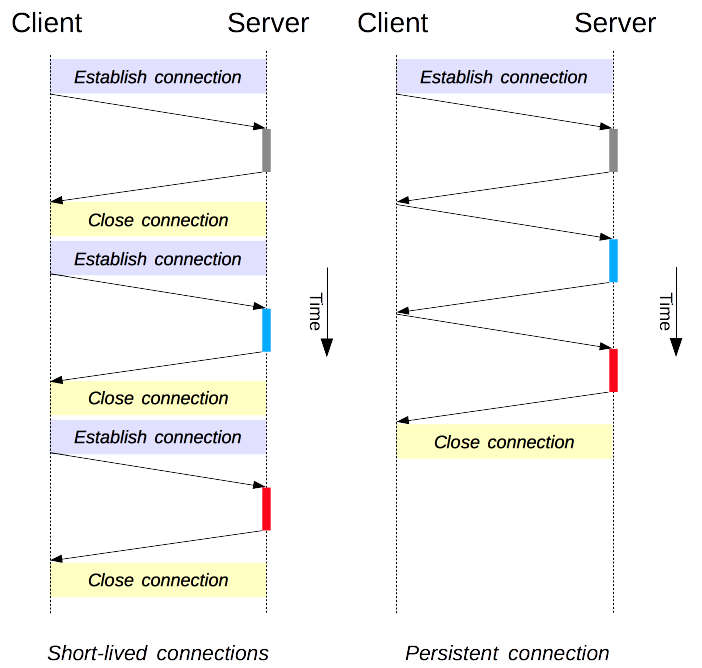
所以要是可以让一次TCP连接保持久一点,每次连接两端多通信几次就好了,也就是图中右边所示,即长连接。这不,HTTP/1.1就支持了。
-
Connection: keep-alive:即表示使用长连接,在HTTP/1.1中默认开启。 -
Connection: close:主动关闭长连接,一般是由客户端发出的。
对于服务端,它也可以设置长连接的断开时机,它们是在Web服务器中配置的。比如在Nginx中,keepalive_timeout代表长连接的超时时间,如果长时间没有数据收发就主动断开连接; keepalive_requests代表长连接过程中最多接收请求多少次。
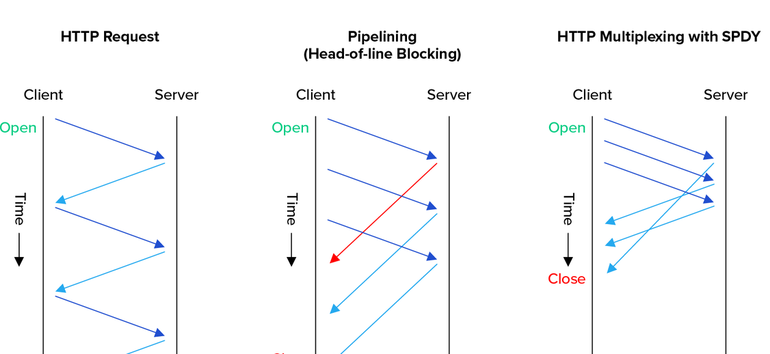
因为长连接的方式,客户端也可以同时发起多个请求,而不必等第一个请求的结果回来再发第二个请求,这也就是管道通信。
不过不管短连接还是长连接,都还会有一个队头阻塞(HoL blocking)问题,这是因为HTTP的“请求-应答”模型规定报文必须是“一发一收”导致的,可以参考下图:
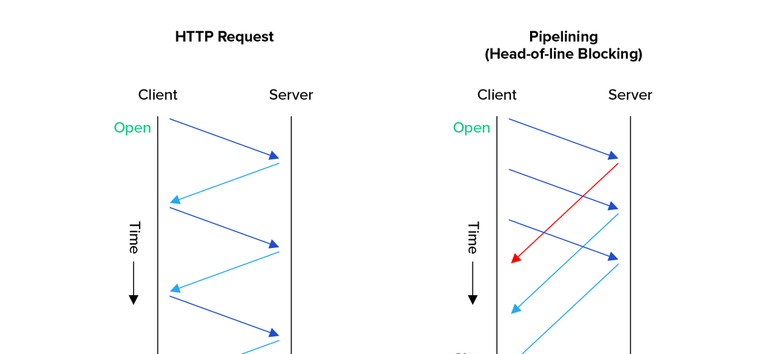
无论如何,接收方都必须先处理完红线请求后,才能处理后面发起的请求,即使后面的请求先到了,也就是“先发必须先处理”。
为了缓解这个问题,有一个办法,就是并发连接,也就是对一个域名发起多个长连接,每个长连接之间互不干扰。但是长连接的保持是需要消耗服务器资源的,而且也可能被恶意攻击,所以规定一般长连接的上限是6~8个。如果还不够用,还有一个取巧的方式,就是域名分片,同一台服务器有多个域名对应,那么上限也就翻倍了。
3)Redirection:重定向相关。
在聊状态码时,我们提到过301(永久)、302(临时),不知道你还记不记得它们的含义。如果返回这种状态码,那么在响应头里一定还会标识重定向的位置。
Location就是重定向的位置,一般有绝对路径和相对路径两种形式,绝对路径对应的就是URL的基本格式,相对路径则没有scheme和host:port,默认使用原请求的URL里的。
和重定向相关的还有3种状态码:303类似302,但请求方法只能是GET;307、308分别类似302、301(这里是反的……),但它们都不允许重定向后的请求有任何变动。
4)Cookie:解决HTTP无状态特点带来的问题。
首先我们要清楚无状态指的是客户端还是服务端?没错,是服务端,也就是服务端不知道收到的这次请求和上次请求有什么关联,那这样会让服务端处理一些特殊场景时方案变得复杂,比如购物。
所以这里Cookie就是来解决这个问题的。简单来说,就是服务端给客户端贴了一个小纸条,标识某个客户端的身份,这个客户端在每次请求时带上这个小纸条,就可以证明自己的身份了。
-
Set-Cookie: a=xxx,Set-Cookie: b=yyy:这是服务端返回的,一个Cookie本质上就是一个键值对,并且每个Cookie是分开的。 -
Cookie: a=xxx; b=yyy:这是客户端在发送请求时带上的,也就是之前服务端返回的Cookie们,它们是合在一起的。
注意,客户端在收到这些Cookie后会将它们保存到客户端里,我们去看看Chrome浏览器就可以发现它们。
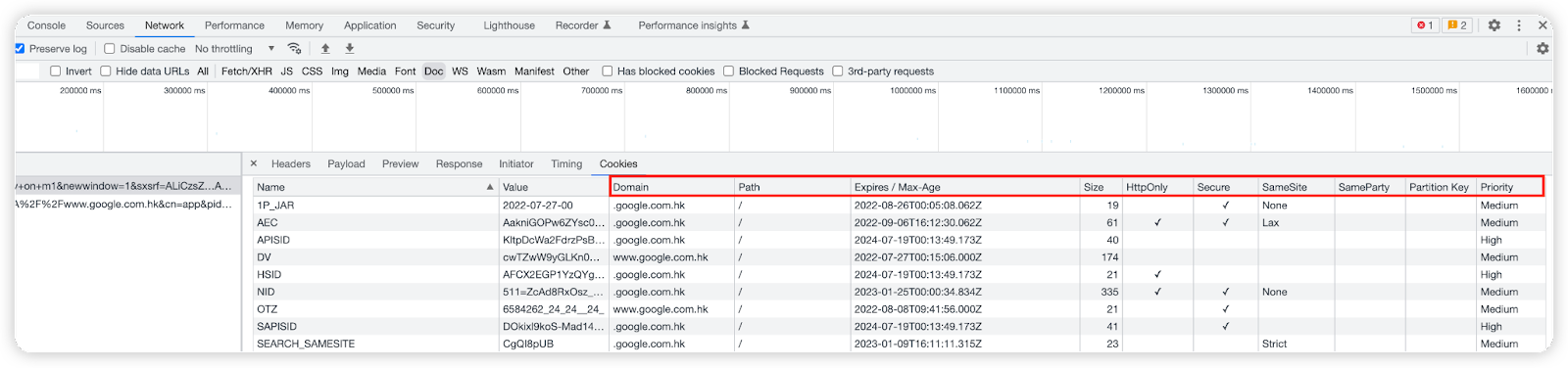
咦?Cookie除了Name和Value,怎么还有这么多属性?其实,服务端返回的Cookie一般长这样:Set-Cookie: a=xxx; Domain=xx; Path=xx; Max-Age=xx; Expires=xx; HttpOnly; Secure; SameSite=xx...。
-
Domain、Path:只有在客户端请求的URL匹配上它们时,这个Cookie才会被带上。
-
Max-Age、Expires:代表Cookie的失效时间,后面Cache也有类似的属性,要注意的是Max-Age的优先级大于Expires。
-
HttpOnly:其为真时,代表这个Cookie只能通过HTTP(S)协议传输,禁止其他方式访问,比如在JS里就不再可以用document.cookie获取它了,以防脚本攻击。
-
Secure:其为真时,代表这个Cookie只有在发起安全的HTTPS请求时,才会被带上。
-
SameSite=xxx:设置SameSite=Strict可以严格限定该Cookie不能跨站发送;SameSite=Lax则略宽松一点,允许在GET/HEAD等安全的请求里使用该Cookie。
5)Cache:缓存相关。
缓存真的无处不在,HTTP请求里也不例外。这里提到的缓存是存放在客户端的,目的就是尽可能地减少网络请求或着返回数据的大小,从而提升网络传输效率。
-
Cache-Control-
服务端可以返回的属性有:
max-age=10/no-store/no-cache/must-revalidate。-
max-age的单位是秒,从返回那一刻就开始计算;
-
no-store代表客户端不允许缓存;
-
no-cache代表客户端使用缓存前必须先来服务端验证;
-
must-revalidate代表缓存失效后必须验证。
-
-
客户端可以发送的属性有:
max-age=0;no-cache。-
一般地,cmd + R刷新页面会带上max-age=0,意思是只要生存了0秒的数据,也就是不走本地缓存了,而是向服务器要一个最新生成的报文;cmd + shift + R强制刷新页面会带上no-cache,和前者基本一致,看服务端如何处理。
-
那什么时候缓存会生效呢?一般是在浏览器前进、后退或者重定向时,客户端发起的请求就不会带上上面的两个属性了。
-
-
此外,为了增加缓存控制的灵活性,这里还有一些条件字段~
-
服务端返回的有:
-
Last-Modified代表文件的最后修改时间。 -
ETag全称是Entity Tag,代表资源的唯一标识,它是为了解决修改时间无法准确区分文件变化的问题。比如一个文件在一秒内修改了很多次,而修改时间的最小单位是秒;又或者一个文件修改了时间属性,但内容没有变化。Etag还分为强Etag、弱Etag:-
前者不变的条件是资源在字节级别不变。
-
后者不变的条件是资源在语义上不变即可,比如多了几个空格之类的。另外,弱Etag的值会在前面加一个
W/标记。
-
-
-
客户端请求时对应就用:
-
If-Modified-Since里放的就是上次请求服务端返回的Last-Modified,如果服务端资源没有比这个时间更新的话,服务端就会返回304,表示客户端用缓存就行。 -
If-None-Match里放的就是上次请求服务端返回的ETag了,如果服务端资源的Etag没变,服务端也是返回304。
-
6)Proxy:代理相关。
代理是具有双重身份的,因为在客户端眼里,它是服务端,而在服务端眼里,它又是客户端。
前面也提到了代理一般分为正向代理和反向代理,反向代理一般被用来做负载均衡(合理分配任务,决定由后面的哪台服务器来响应请求)、安全防护、加密卸载(在内网里通信就不加密了,减少加解密成本)、内容缓存(暂存服务器响应,这个下面会说,也就是代理缓存)等等。

在上面有代理服务器的场景中,涉及到的头字段是:
Via:代理服务器会在发送请求时,把自己的主机名加端口信息追加到该字段的末尾。
但是服务器一般需要知道客户端的真实IP信息,方便做访问控制、用户画像、统计分析等,所以在HTTP标准外还约定了下面的头字段:
-
X-Forwarded-For:类似Via的追加方式,但追加的内容是请求方的IP地址。 -
X-Real-IP:只记录客户端的IP地址,它更简洁一点。
不过上面的方式其实有一个很大的缺点:损耗性能!因为每次代理服务器需要解析出HTTP报文头,再修改报文数据;而且在有些情况下,报文是不允许甚至是不能(加密)被修改的。所以后来就又出现了一个专门的代理协议,这也是在标准外约定的。
基于这个协议,代理服务器只需要在HTTP报文前再加一行文本即可。比如:
PROXY TCP4 1.1.1.1 2.2.2.2 55555 80\r\n
GET / HTTP/1.1\r\n
Host: www.xxx.com\r\n
\r\n
-
开头是
PROXY五个大写字母; -
然后是客户端的 IP 地址类型,如
TCP4或者TCP6; -
再后面是请求方、应答方的地址,以及请求方、应答方的端口号;
-
最后用一个回车换行结束。
7)Proxy Cache:代理缓存相关。
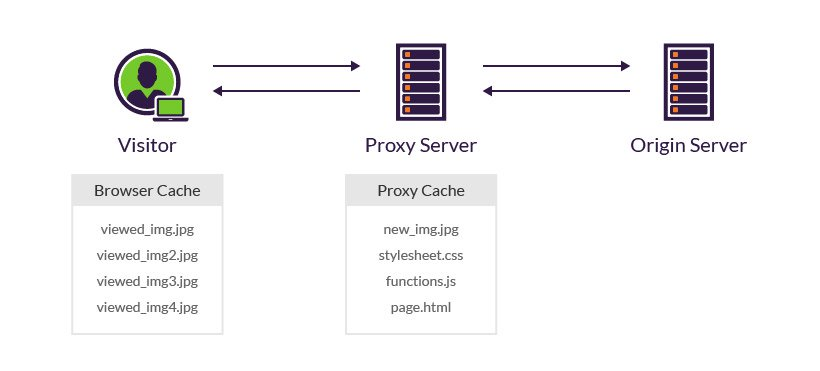
客户端可以缓存,中间商代理服务器当然也可以缓存。但因为代理的双重身份性,所以Cache-Control针对代理缓存还增加了一些定制化的属性~
-
从服务端到代理服务器:
private代表数据只能在客户端保存,不能缓存在代理上与别人共享,比如用户的私人数据。public代表数据完全开放,谁都可以缓存。s-maxage代表缓存在代理服务器上的生存时间。no-transform代表禁止代理服务器对数据做一些转换操作,因为有的代理会提前对数据做一些格式转换,方便后面的请求处理。
-
从客户端到代理服务器:
-
max-stale代表接受缓存过期一段时间。 -
min-fresh则与上面相反,代表缓存必须还有一段时间的保质期。 -
only-if-cached代表客户端只接受代理缓存。如果代理上没有符合条件的缓存,客户端也不要代理再去请求服务端了。
-
8)Others
我们再看看这张常见头字段图,你是不是已经清楚每一个头字段的含义和用法了呢~
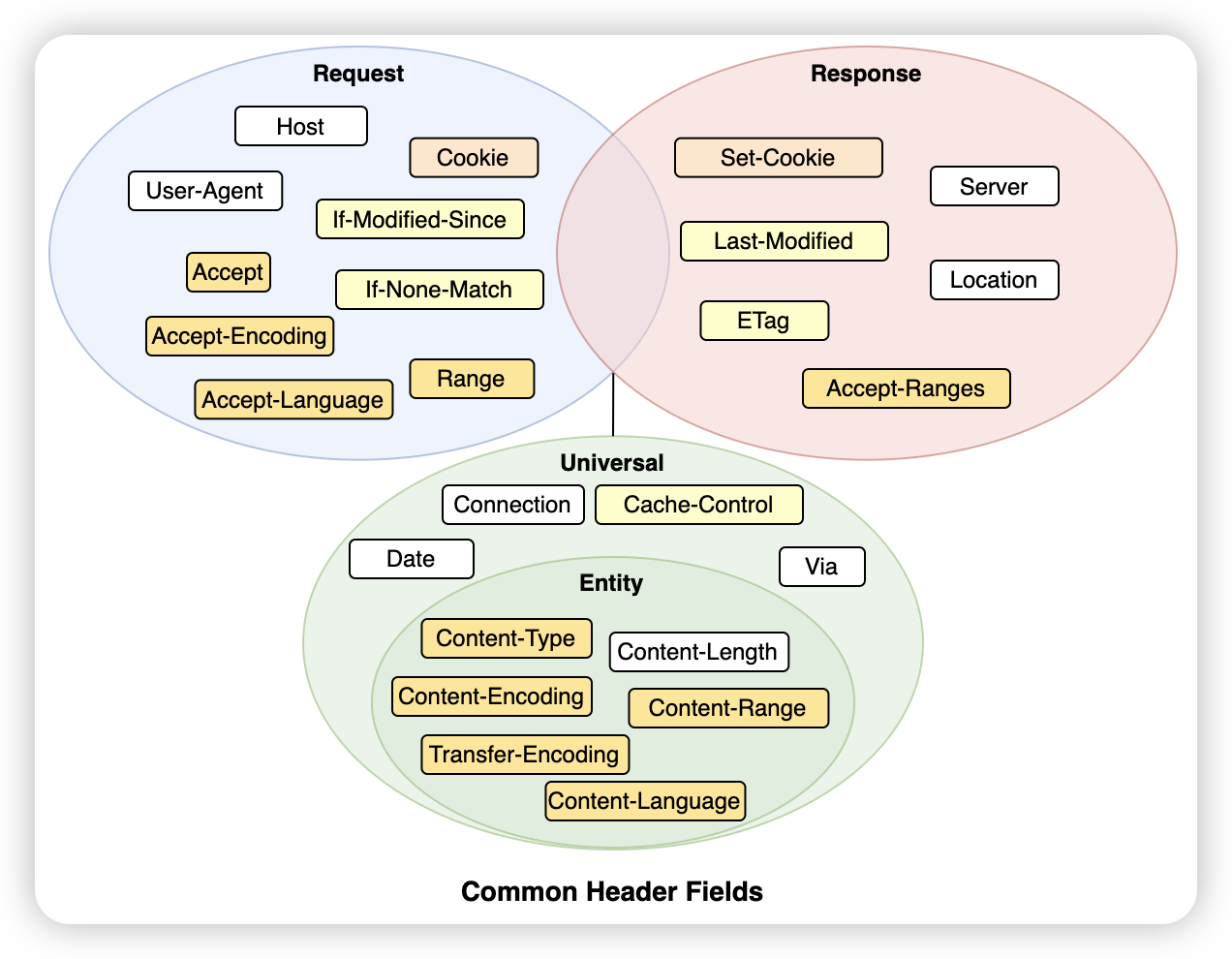
等等,上面还漏了一些头字段的说明,我把它们统一放在这里补充一下:
-
Host代表要请求的主机名。它在HTTP/1.1里是必须出现的,用来给服务器区分具体选择哪个主机来处理请求的(如果计算机上托管了多个虚拟主机就有这个作用,否则服务器一般也不会去处理)。另外,在一般的网络框架里,它会帮我们从URL里解析出一个默认的Host值兜底,所以可能你没有手动填也没有问题,因为框架默认帮我们补充了。 -
User-Agent即用户代理,它是用来描述请求方的身份的,服务器可以根据它来返回合适的页面布局或者数据。不过由于历史原因,它的用法已经有些混乱了,比如每个浏览器都自称是“Mozilla Chrome Safari”之类的。 -
Date代表报文创建的时间,一般出现在响应头里。 -
Server展示的是提供Web服务的软件名称和版本号,但这样暴露了服务器的部分信息,可能存在安全隐患,所以有的时候返回里没有这个字段,或者仅仅是一个模糊的信息。 -
Content-Length代表报文里body的长度。如果没有这个字段,那么一般会有另一个字段Transfer-Encoding: chunked,前面我们说到过它。
至此,我们已经讲完了什么是HTTP了,可以试着用Chrome开发者工具或者WireShark抓包加深理解。
什么是HTTPS?
HTTPS比HTTP多了一个S,这个S代表的是SSL/TLS协议。
现在来到了我们的第三个目标:🔐了解基本的加密知识。
这一节因为之前写过相关文章,所以我尽量减少篇幅,你可以点击下面的链接参考:
-
信息安全 | 互联网时代,如何建立信任?:三大常见密码学算法,数字签名,数字证书。
-
信息安全 | (加餐)互联网时代,如何建立信任?:SSL/TLS,SSH,iOS签名,OpenSSL、WireShark实践。
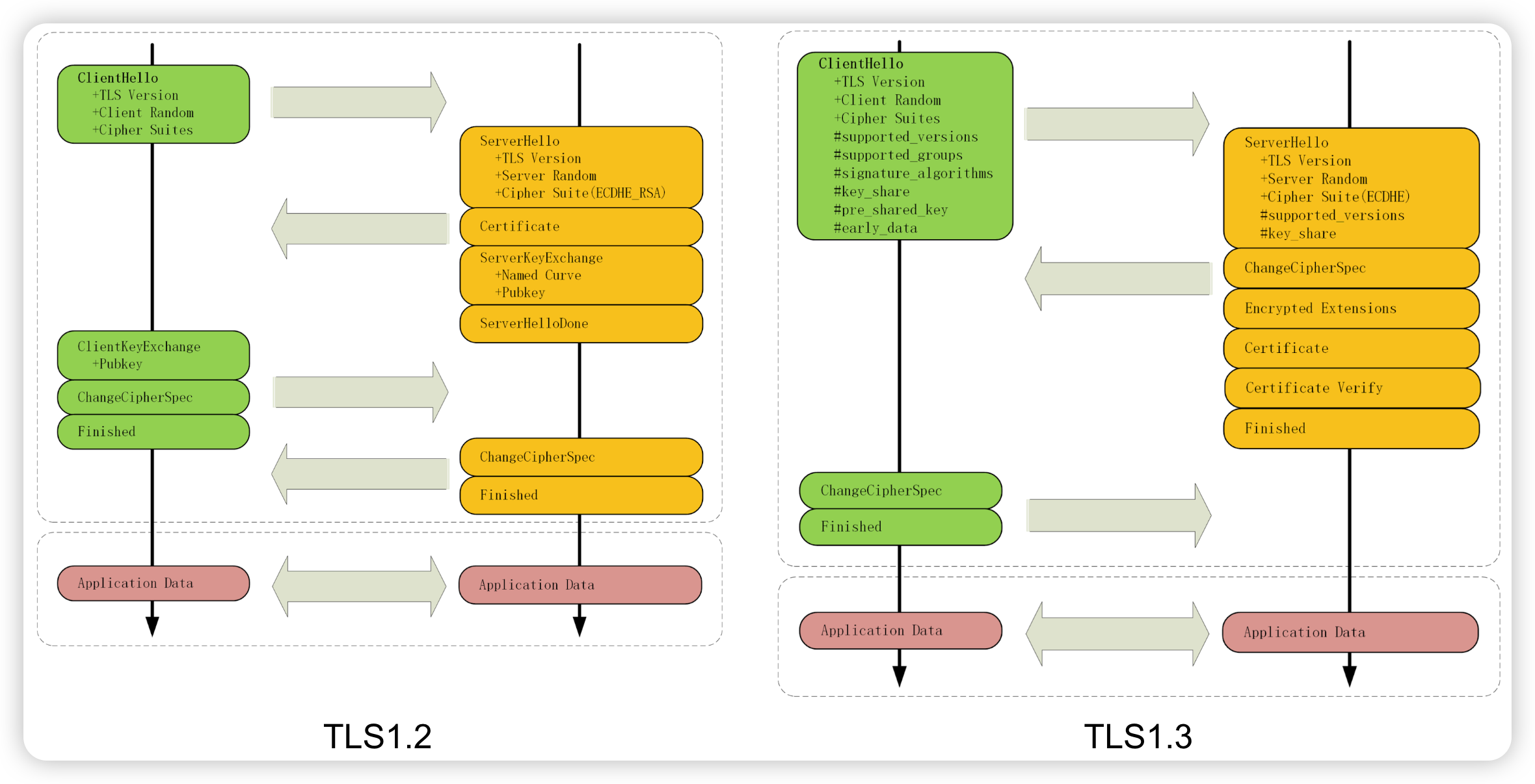
要补充的一个内容是:基于ECDHE的TLS主流握手方式 VS. 基于RSA的TLS传统握手方式。
两者的关键区别在于通信密钥生成过程中,第三个随机数Pre-Master的生成方式:
-
前者:两端先随机生成公私钥,同时公钥(加签名)作为参数传给对方,然后两端基于双方的参数,使用ECDHE算法生成
Pre-Master; -
后者:客户端直接生成随机数
Pre-Master,然后用服务器证书的公钥加密后发给服务器。
因为前者的公私钥是随机生成的,即使某次私钥泄漏了或者被破解了,也只影响一次通信过程;而后者的公私钥是固定的,只要私钥泄漏或者被破解,那之前所有的通信记录密文都会被破解,因为耐心的黑客一直在长期收集报文,等的就是这一天(据说斯诺登的棱镜门事件就是利用了这一点)。
也就是说,前者“一次一密”,具备前向安全;而后者存在“今日截获,明日破解”的隐患,不具备前向安全。
更多的细节可以参看《透视HTTP协议》里TLS1.2连接过程解析这一课,或者自己用WireShark抓包试一试~
两者从抓包上的区别来看,主要是:
-
前者比后者多了一个“Server Key Exchange”消息。
-
前者客户端可以不等连接完全建立就提前进行加密通信,也就是客户端不用等服务器发回“Finished”确认握手完毕,这个叫“TLS False Start”。
HTTP的发展
我们通过下面表格梳理一下HTTP的发展过程,今天我们对HTTP发展有一个整体的认知就好~
| Time | Version | Main change | Note |
|---|---|---|---|
| 1989 | 3 key technologies | HTML, URI, HTTP | Paper from Tim Berners-Lee. |
| 1991 | HTTP/0.9 | 1. Request way: GET. 2. Data: HTML. | No RFC. |
| 1996 | HTTP/1.0 | 1. +Request way: HEAD, POST. 2. +Data: img, audio. 3. +Other: HTTP Head, status code, protocol version. | RFC-1945 (1996). Not a formal standard. |
| 1999 | HTTP/1.1 | 1. +Request way: PUT, DELETE. 2. +Cache-control. 3. +Keep-Alive. 4. +Pipeline transmission(Content-Length), chunked transmission. 5. +Host head (Required). | +Google, Sina, Sohu, Netease, Tencent. RFC-2616 (1999). +Facebook, Twitter, Taobao, JD. Divided to RFC-7230~7235 (2014). RFC-9112 (2022). |
| 2015 | HTTP/2 | 1. Transmission data format: text → binary data. 2. +Concurrent requests (use stream, abandon pipeline transmission). 3. +Header Compression. 4. +Allow the server to push. 5. +Combined with TLS 1.2+. | Based on SPDY in Chrome browser (2009). RFC-7540 (2015). RFC-9113 (2022). |
| 2022 | HTTP/3 | 1. Transport layer protocol: TCP → QUIC (based on UDP, including TLS 1.3, IP:port → connection ID). 2. Header Compression: HPACK→QPACK | Based on QUIC in Chrome browser(2012). RFC-9114 (2022). |
-
从HTTP/1.0开始,HTTP已经被写入RFC文档(RFC文档汇总)。
-
HTTP/1.1是HTTP第一个正式标准,大多数的功能我们在常见头字段那一节介绍了。在这个阶段早期,Google、Sina、Sohu、Netease、Tencent等公司被创立了,后期Facebook、Twitter、Taobao、JD等公司慢慢也出来了。
-
HTTP/1.1在各方面还比较完善了,但在性能和安全上还存在很大优化空间。所以HTTP/2、HTTP/3都主要是针对HTTP的性能方面做优化。
- HTTP/2基于Chrome的SPDY协议,它是Chrome推动的。主要的变化有:
-
传输数据格式从文本转成了二进制,大大方便了计算机的解析。
-
基于虚拟流的概念,实现了多路复用能力,同时替代了HTTP/1.1里的管道功能。
-
利用HPACK算法进行头部压缩,在之前都只针对body做压缩。
-
允许服务端新建“流”主动推送消息。比如在浏览器刚请求HTML的时候就提前把可能会用到的JS、CSS文件发给客户端。
-
在安全方面,其实也做了一些强化,加密版本的HTTP/2规定其下层的通信协议必须在TLS1.2以上(因为之前的版本有很多漏洞),需要支持前向安全和SNI(Server Name Indication,它是TLS的一个扩展协议,在该协议下,在握手过程开始时通过客户端告诉它正在连接的服务器的主机名称),并把几百个弱密码套件给列入“黑名单”了。
-
PS:相比HTTP/1.1中的并发连接方式,虚拟流的概念更优美地解决了HTTP的队头阻塞问题。
- HTTP/3基于Chrome的QUIC协议,它也是Chrome推动的。
-
先看看QUIC
-
基于UDP实现了可靠传输,引入了类似HTTP/2的流概念。
-
内含了TLS1.3,加快了建连速度。
-
连接使用“不透明”的连接ID来标记两端,而不再通过IP地址和端口绑定,从而支持用户无感的连接迁移。
-
-
回到HTTP/3
-
它最大的改变就是把下层的传输层协议从TCP换成了QUIC,完全解决了TCP的队头阻塞问题(注意,是TCP的,不是HTTP的),在弱网环境下表现更好。因为 QUIC 本身就已经支持了加密、流和多路复用等能力,所以 HTTP/3 的工作减轻了很多。
-
头部压缩算法从HPACK升级为QPACK。
-
2022年6月6日,HTTP/3被正式写入RFC文档,同时,HTTP/1.1和HTTP/2也更新了RFC文档。
-
-
PS:TCP为了保证可靠传输,有个特别的“丢包重传”机制,即丢失的包必须要等待重新传输确认,其他的包即使已经收到了,也只能放在缓冲区(kernel)里,上层的应用(user)拿不出来,可参考下图:红色方块请求是阻塞TCP的关键。
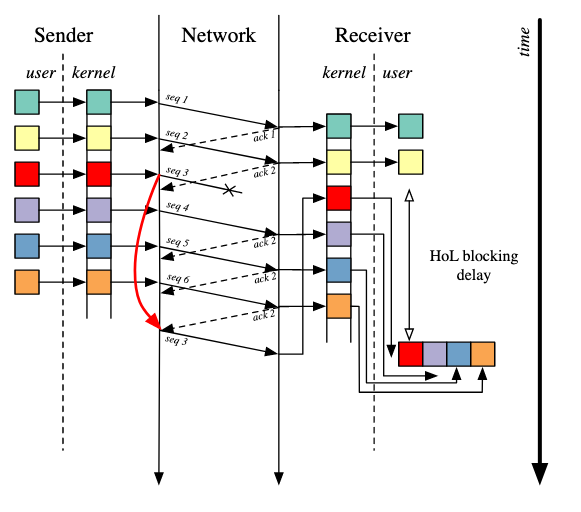
(其实这里有一点疑惑的是,合着HTTP/3之前解决的都只是kernel到user的阻塞问题?具体地说只是经过TCP之后的阻塞问题,在这个阶段的阻塞问题有哪些呢🤔?欢迎大佬们答疑解惑~)
HTTPS的发展
这部分聊聊TLS1.2到TLS1.3的发展,在此之前的版本因为各种安全问题都已经被废弃了,我们可以从信息安全 | (加餐)互联网时代,如何建立信任?这篇文章里了解到。
对于TLS1.3来说,它的主要优化目标有3个:
-
兼容TLS1.2。为了保证老设备能够更轻松地升级协议,TLS1.3保持原有的记录格式不变,利用扩展协议在原有记录末尾增加一些“扩展字段”来增加新的功能,老版本的 TLS 不认识它们可以直接忽略,从而实现了“后向兼容”。
-
更安全。TLS1.3基于安全考虑对支持的密码套件进行了瘦身,最终只剩下5个密码套件。前面提到的基于RSA的TLS传统握手方式就被废除了。
-
更高性能。HTTPS建立连接的过程除了TCP握手,还有TLS握手,在TLS1.2中TLS握手需要花费2-RTT,而这个时间在TLS1.3中被优化到了1-RTT。怎么做的呢?
-
答案就在上一点中,因为密码套件只有这么多,TLS1.3可以索性在ClientHello消息中带上所有支持的密码套件相关参数,服务端选定其中一种就可以直接生成通信密钥进行加密通信了!而客户端也省去了TLS1.2中要等服务端确认密码套件后再发参数的过程。
-
除了标准的1-RTT握手,TLS1.3在之前建立过连接从而缓存了服务端密码套件参数的情况下,还可以达到0-RTT握手,但这也存在前向不安全和重放攻击的问题,所以需要使用者去权衡。
-
下面我再放上《透析HTTP协议》里的通信过程对比图,你可以再看看它们的差异。
-
尾声(好消息)
好啦,今天就聊到这里啦,回到我们的目标,看看你还能想到具体的知识吗?
-
🔍 快速定位HTTP问题。
-
🥣 熟悉HTTP报文里的常见头字段。
-
🔐了解基本的加密知识。
当然,别忘了我们的终极目标🏁:如果你对HTTP感兴趣,试着通过WireShark、Chrome、Telnet工具以及RFC文档,去自行深入学习HTTP吧~
这里是Bo2SS,咱们下次再见!
插播一条好消息,经过一年多的佛系经营,在2022年8月14日10时45分,Bo2SS的粉丝基数悄悄突破500啦🎉!大家快来帮忙想想怎么庆祝(薅)一下Bo2SS?欢迎投票,或在下方留言!
投票:
A. 发发红包,沾沾运气
B. 赠送书本,汲取知识
C. 建交流群,促进友谊
D. 别玩了,继续出文章
E. 都可以,不要白不要
F. 都不行,我去留言啦

