
课程内容
数组的定义与初始化
- 定义:存储一个固定大小的相同类型元素的顺序集合
- 初始化
- int a[100] = {2, 3}; // a[0] = 2, a[1] = 3
- int a[100] = {0}; // 数组的清空操作:数组每一位都初始化为0值
- 其实只是定义了第0位为0,但会引发其他位自动初始化为0
- 其他
- 从下标0开始
- 数组空间大小:所有变量大小的总和
- 存储空间连续
- int a[3]
| 地址 | 0123 | 4567 | 89[10][11] |
|---|---|---|---|
| 元素 | a[0] | a[1] | a[2] |
-
- 上述定义的数组都属于静态数组
- 不建议的操作:int n; scanf("%d", &n); int arr(n);
- 下标-值的映射
- 已知索引,取值的时间效率是O(1)
- 上述定义的数组都属于静态数组
素数筛
核心思想:用素数去枚举掉所有合数
- 当作一个算法框架去学习,有很多演变
- 素数:只有1和它本身两个因子
- 1既不是素数也不是合数
- 2是最小的素数
- 素数一定是奇数(除了2),奇数不一定是素数
- 借助数组结构。数组可以表示三种信息:
- 下标
- 下标映射的值
- 值的正负
- 算法衡量标准及该算法性能
- 空间复杂度:O(N),有N个数字就开辟大小为N的数组
- 时间复杂度:O(N * logN)、O(N * loglogN)--优化版,趋近于O(N)
- 不是O(N),是因为有重复标记情况
- log以谁为底不重要,以2为底就已经很小了
- 怎么计算:均摊思想,根据时间复杂度与概率来算期望...
- 打标记:素数,0;合数,1
- 借助数组的两种状态信息:下标→数字,值→标记
- 素数筛扩展
- 求一个范围内所有数字的最小、最大素因子
- 比如12:2、3
线性筛
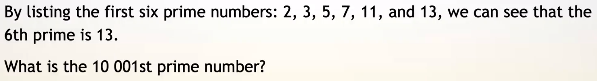
- 从欧拉第7题入手
- 求第10001个素数
- 可以使用枚举法 O(N * sqrt(N))、素数筛
- 估算第10001位素数大小不会超过多少?
- 规律:20万以内排名的素数,其范围不会超过排名的20倍
- 来自素数筛的思考
- 6被标记了几次?2次:2、3
- 30被标记了几次?3次:2、3、5
- 如果一个数字N的素数分解式中,含有m种不同的素数,N被标记几次?m次
- 那么可不可以只被标记1次呢?👇
- 线性筛
- 空间、时间都是O(n)
- 用一个整数M去标记合数N
- M、N的关系符合四个性质
- N的因子中最小的素数为p
- N = p * M
- ❗ p一定小于等于M中最小的素因子
- 类似七擒孟获的道理,只在最后一次标记
- 利用M * P' (所有不大于【M的最小素数】的素数集合)标记N1、N2、...
【i 和 iii 有点等价的意味】
- 代码
-
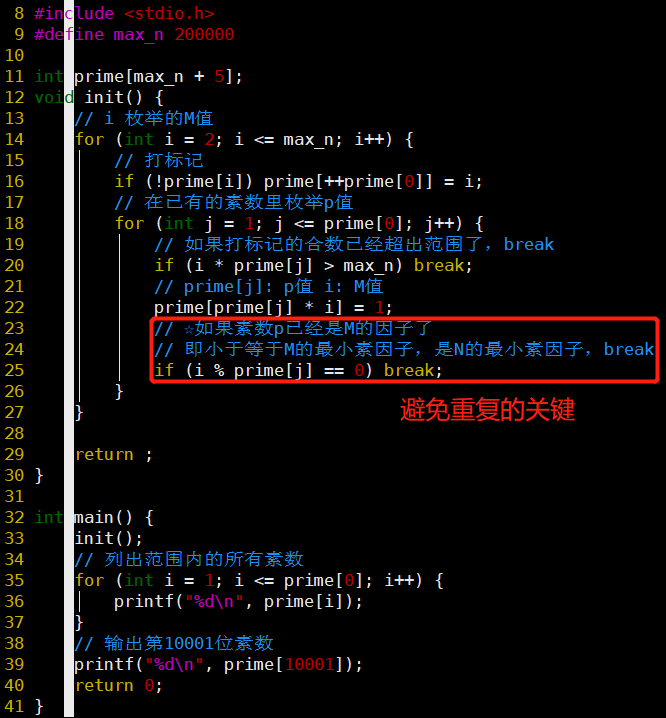
- 核心思想:N = M(↑尽可能大) * p(↓尽可能小)
- 枚举M,慢慢增大p值,直到p值满足终止条件:性质iii
- 相比M,p更好控制!
- 避免重复的关键就是第iii条性质
- 注意:虽然有两层for循环,但时间复杂度是O(N),因为第二层for循环里的break,整个数组就遍历一次
- 与素数筛初始条件优化为 i * i 的区别是?素数筛还是有重复标记的情况
-
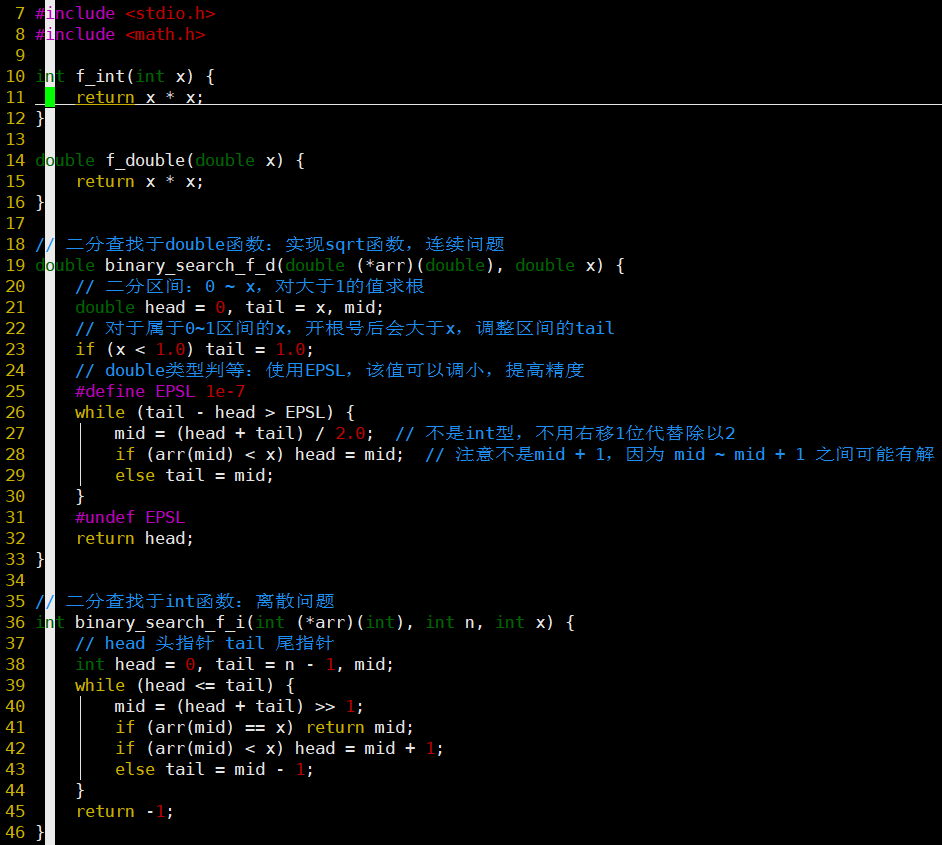
二分查找法
-
顺序查找→折半查找:O(N)→O(logN)
-
关键前提:查找序列单调
-
代码
-
-
-
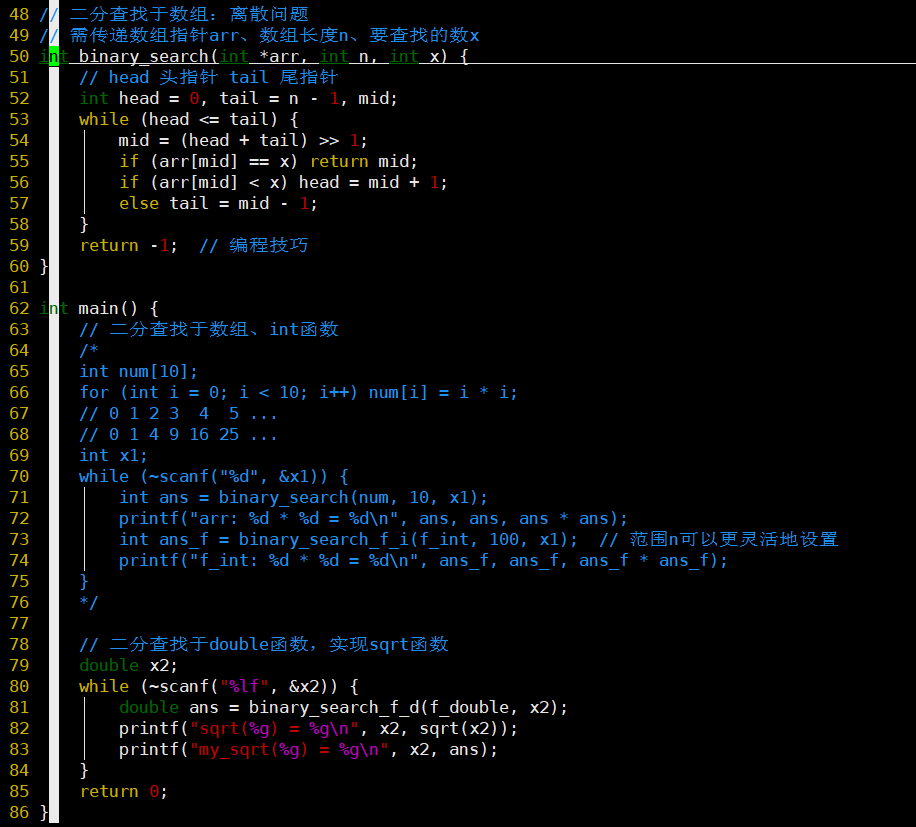
主要演示三个部分:①在数组中二分查找 ②在函数中二分查找 ③
-
对于函数的二分查找实现部分
- 应该可以把binary_search_f_i和binary_search_f_d统一为一个函数
- 关注后面的学习,可否辨识传入的函数指针的返回类型
- 但实现部分有差别,因此意义应该不大
-
main函数中被注释的代码,测试的是在数组与函数中二分查找的结果,如下:
-
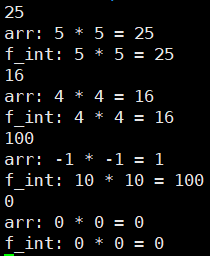
- 利用函数做二分查找的范围可以更灵活
-
double类型判等:用差值小于EPSL判断
- 记得#undef EPSL
-
细节详见注释
- 学习顺序:binary_search 👉 binary_search_f_i 👉 binary_search_f_d
-
-
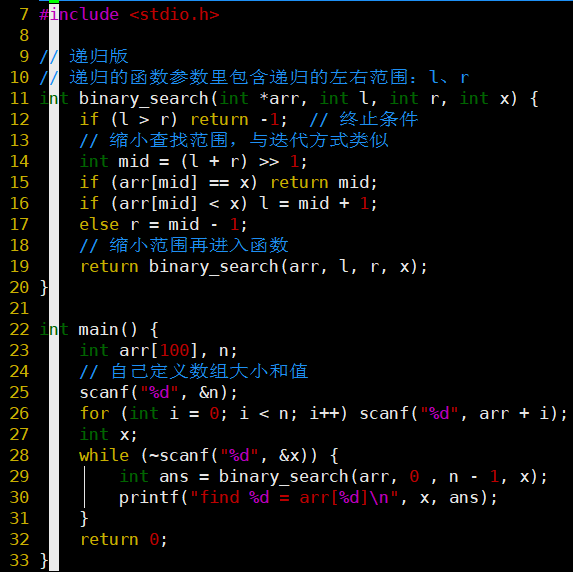
递归版代码
-
-
函数的参数与迭代方式有所不同,需确定查找边界
-
牛顿迭代法
-
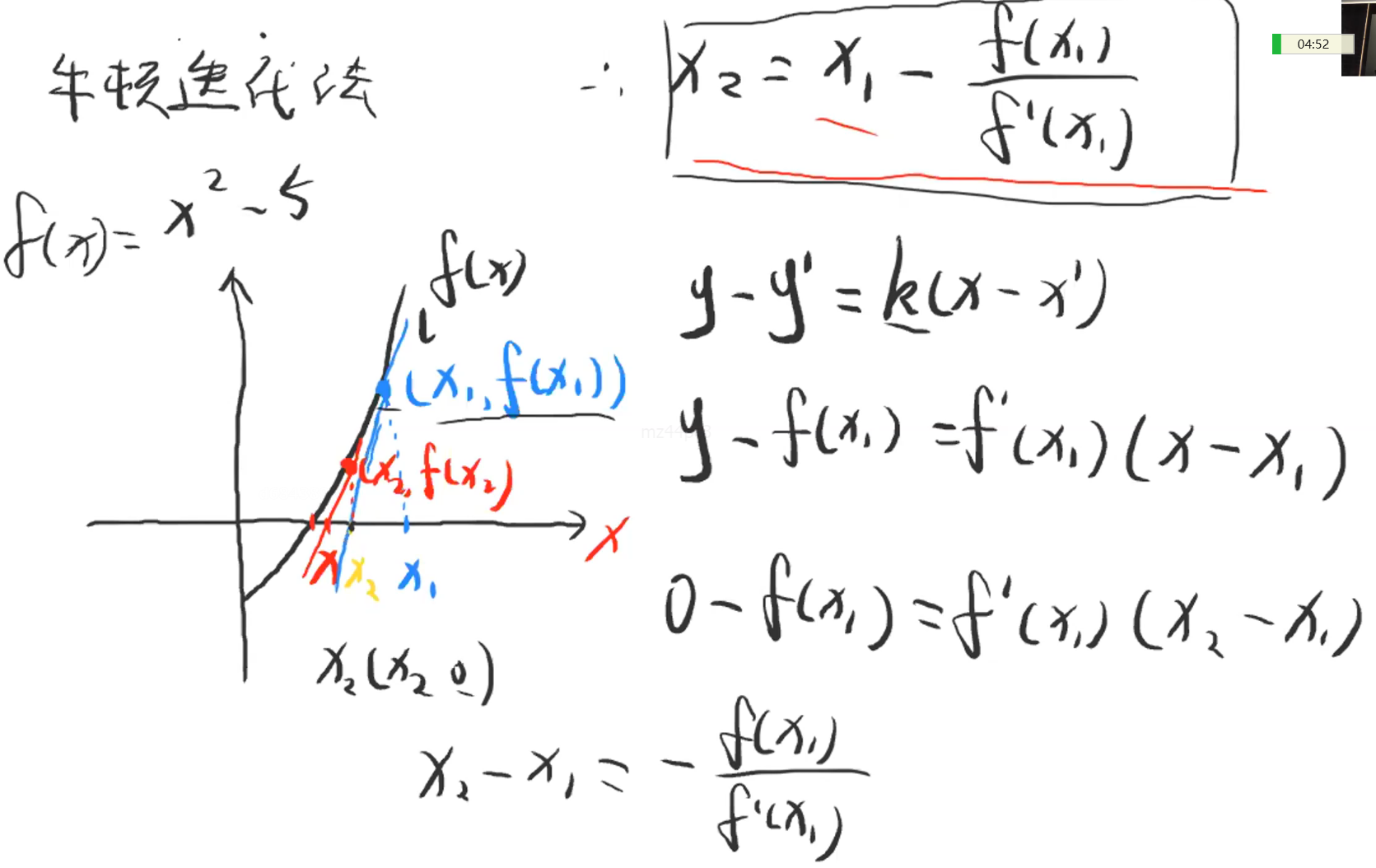
-
目的:求解f(x) = 0时x的值
-
条件:函数可导;收敛
-
迭代一次公式:x2 = x1 - f(x1) / f'(x1)
-
核心思想:每迭代一次,x2会比x1更接近要求的x的值,直到f(x)的绝对值比EPSL小即可
-
代码
-
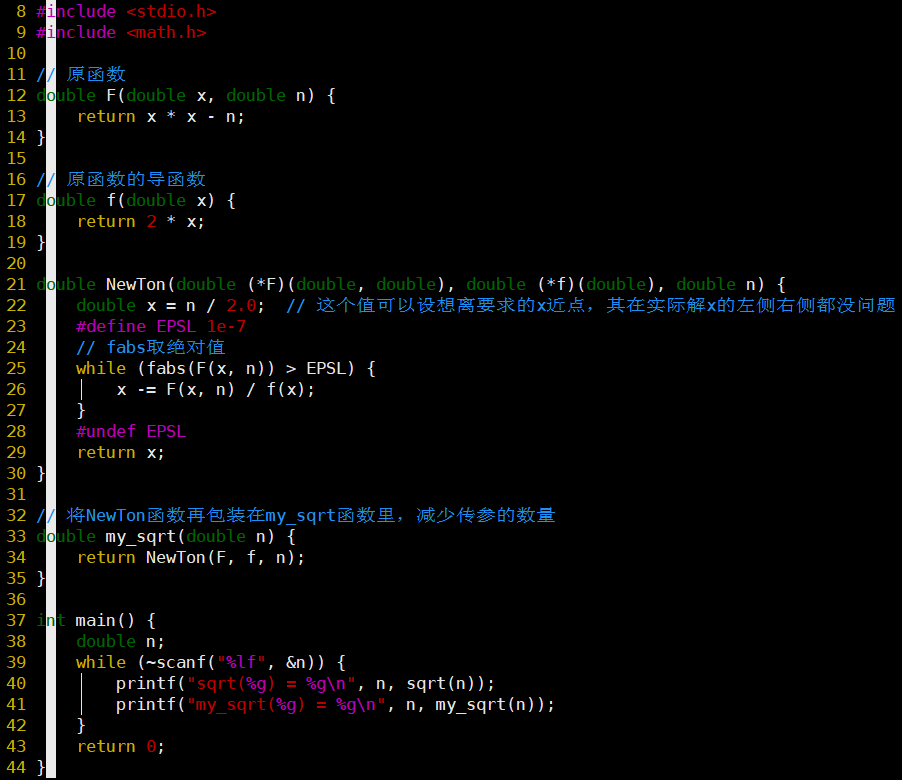
-
⭐循环终止条件记得取绝对值!
-
x = n / 2.0这个初始值是固定的吗?
- 不是
- 这个值是设想的x最近的解,在解的左右两侧都没问题
- 不过不能取0哈,因为导数为0,会导致除数为0
-
对NewTon函数做一个包装,得到my_sqrt函数
-
不是二分查找!二分需要单调~
-
预处理命令
- #开头的命令
- #include <stdio.h> →在预处理时,将stdio.h文件原封不动地拷贝到当前位置
- 宏定义
- 定义符号常量:常量→符号。
#define PI 3.1415926
#define MAX_N 1000
- 便于批量修改值
- 傻瓜表达式
#define MAX(a, b) (a) > (b) ? (a) : (b)
#define S(a, b) a * b
- 傻 eg. #define S(a, b) a * b
- S(2 + 3, 4 + 5) → 简单替换 → 2 + 3 * 4 + 5 等价于 2 + (3 * 4) + 5
- 在替换过程中不做任何运算!
- 定义代码段(高级)
#define P(a) { \
printf("%d\n", a); \
}
-
宏只能接受一行定义,换行需要使用反斜杠 '' (连接符)
-
预定义的宏(系统封装好的)
-
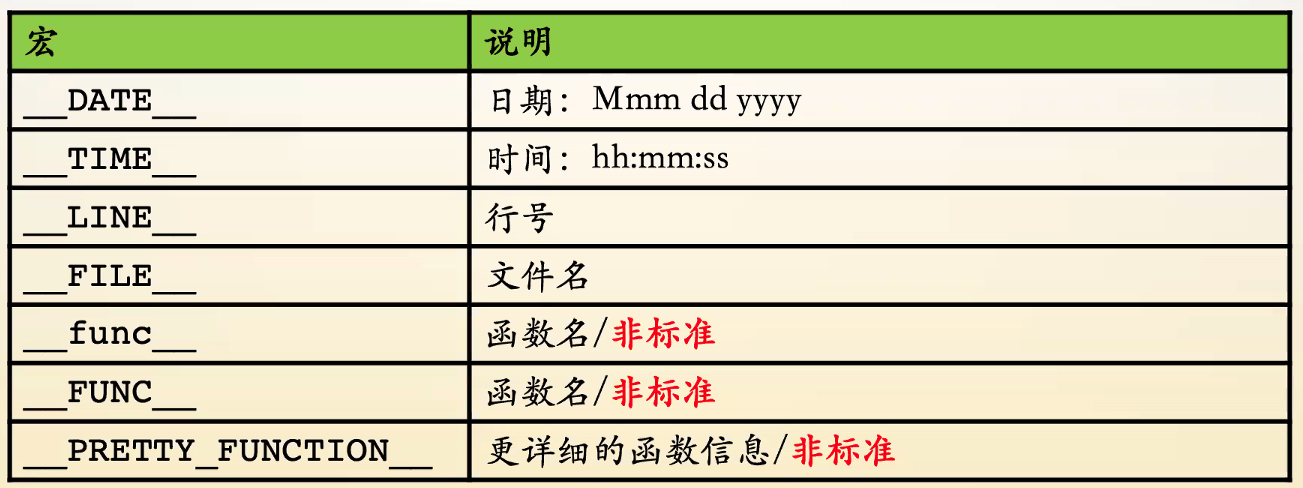
-
宏的两端是两个下划线
-
DATA、TIME:预编译时的日期、时间,不预处理就不会改变
- 可以实现类似指纹识别的功能?预存储的关系?
-
非标准宏:有的环境可能未定义,不同环境的标准可能不同,所以可移植性不好
- 怎么处理呢?可以使用条件式编译👇
-
-
条件式编译
- #ifdef DEBUG
- 说明:是否定义了DEBUG宏
- 注意:DEBUG一定是一个宏,而不是变量!
- 宏在预编译后生效,变量在编译后生效
- #ifndef DEBUG 是否没定义
- #if MAX_N == 5 宏MAX_N是否等于5
- 可在游戏中判断用户手机版本
- #elif MAX_N == 4
- #else
- 一定要以#endif结束!!!
- 【编码规范】
- 如同va_start、va_end
- #ifdef DEBUG
-
简易编译过程
-
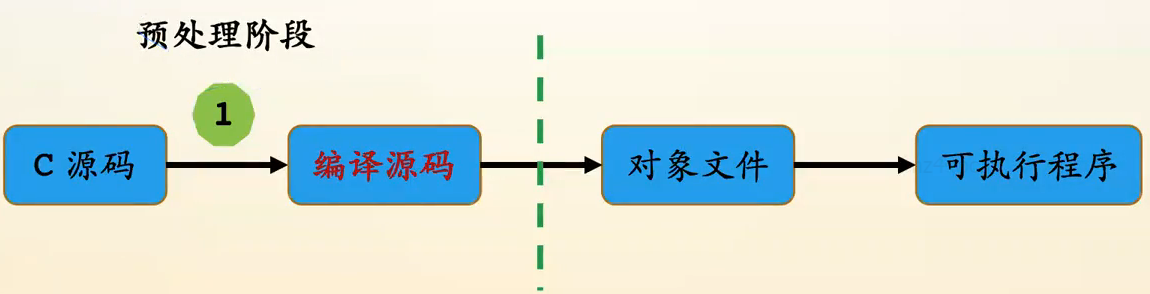
-
C源码 .c
👇预处理阶段(预编译) (gcc -E):包含头文件、宏替换等预处理命令,替换所有的#命令
- 编译源码 .c
👇语法检查、编译 (gcc –S)
- 汇编源码 .s、.asm
👇汇编 (gcc -c)
- 对象文件 .o(linux下)或 .obj(windows下)
👇链接 (gcc)
- 可执行程序 a.out(linux下)或 a.exe(windows下) (二进制文件)
PS:最后还有一个装载过程,主要是建立可执行文件、虚拟地址、物理地址三者的映射关系
-
字符串
- 字符数组
- 定义:char str[size];
- 初始化
char str[] = "hello world";
char str[size] = {'h', 'e', 'l', 'l', 'o'};
-
Line1
- []里可不指明大小,系统会自动算
- 系统会自动加终止符'\0',字符数组大小:11+1
-
Line2
- size至少为6,考虑终止符'\0'占一位
- 多余的位都补'\0'
- 如果不加size,就要在数组最后加字符'\0',系统不会自动加
- size至少为6,考虑终止符'\0'占一位
-
'\0'
- 一个终止标记位
- 底层对应0值:false
- '\0'可作为终止条件,如:for循环读入字符串
-
字符后面会有'\0'吗?没有,是字符串的特性
-
相关操作
-
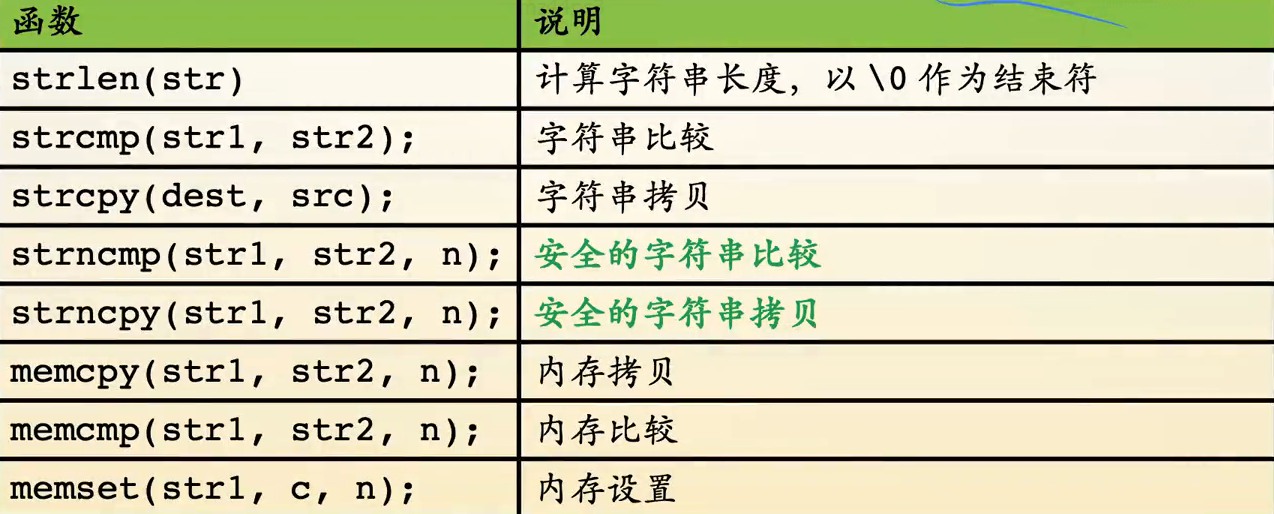
-
头文件:<string.h>
-
strlen(str)
- 返回字符'\0'的下标,长度不含'\0'
- PS:sizeof()会考虑变量实实在在占用的内存,会考虑'\0',单位为字节
-
strcmp(str1, str2);
- 按字典序比较ASCII码大小
- 从第一位开始
- 返回值为差值(相等即为0)
- 按字典序比较ASCII码大小
-
strcpy(dest, src);
-
比较和拷贝的结束标志:找字符'\0',如果'\0'丢了呢?所以有
-
更安全的比较与拷贝:strncmp、strncpy
- 针对'\0'不小心丢了的情况
- 最多比较、拷贝n个字节
-
内存相关
-
memset(str, c, n)
-
不局限于字符串操作,str对应一个地址即可
-
这里举例对数组的操作
-
memset(arr, 0, sizeof(arr))
- 初始化,清空为0
-
memset(arr, 1, sizeof(arr))
- 这里不是把每位置为1,因为操作的是每个字节,而int占4个字节
- 0000...01000...001000....0001...
-
memset(arr, -1, sizeof(arr))
- 确实是-1,因为-1在1个字节里就是11111111
-
-
-
-

-
头文件:<stdio.h>
-
两者结合可以做格式拼接:一个读入,一个输出
-
scanf里的str1类比于终端的输入,它被换成了字符串输入
随堂练习
实现没有BUG的MAX宏
-

-
思路:①手算正确输出👉②先写最简单的有BUG的实现,并有友好的输出显示👉③针对错误输出依次找问题,解决
-
①正确输出如图
-
②先写有BUG的,并实现友好的输出显示
#define MAX(a, b) a > b ? a : b
#define P(func) { \
printf("%s = %d\n", #func, func); \
}
- Line2-4:友好输出显示
- #func直接输出其字符串表示
- 不加#就是调用其值
- ③针对错误输出依次找问题,解决
-
(解决BUG的顺序也很重要,不过这里BUG的顺序很好)
-
这个时候看下错误情况
-
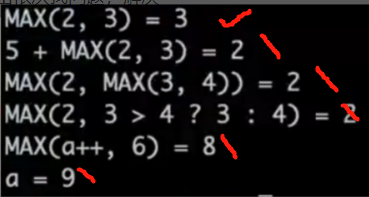
-
因为宏导致的错误,可以看预处理后的文件
- gcc -E *.c 输出预处理替换掉宏之后的代码
-
第一次纠错
-
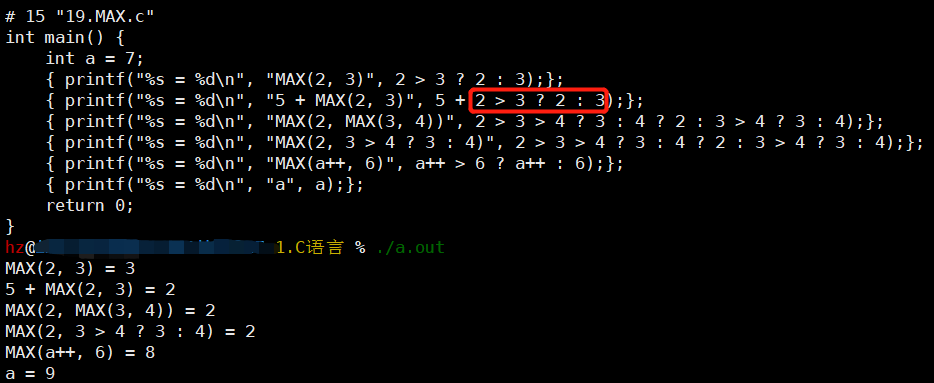
- 解决:可以将红框处用括号提高优先级
-
-
#define MAX(a, b) (a > b ? a : b)
-
- 第二次纠错
-
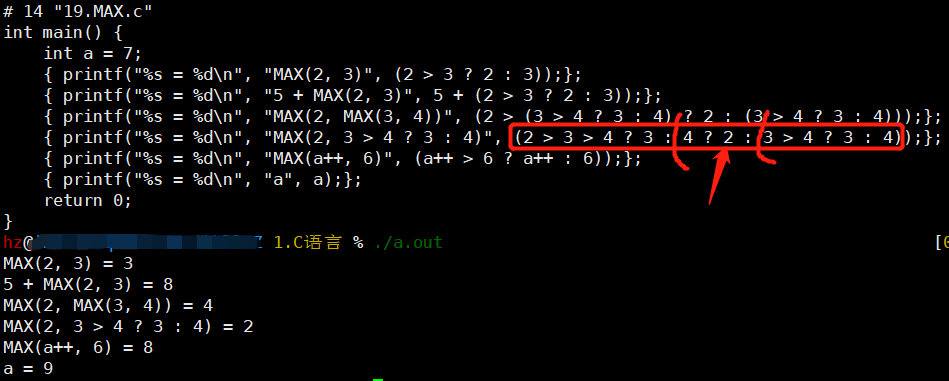
-
第四个结果为2,思路如上图
-
注意条件运算符 '?:'
-
优先级很低:比'>'低
-
有多个'?:'存在时,其结合方向是右到左
-

-
-
解决:对于每个变量再用括号提高优先级
-
- 第二次纠错
#define MAX(a, b) ((a) > (b) ? (a) : (b))
-
- 第三次纠错
-
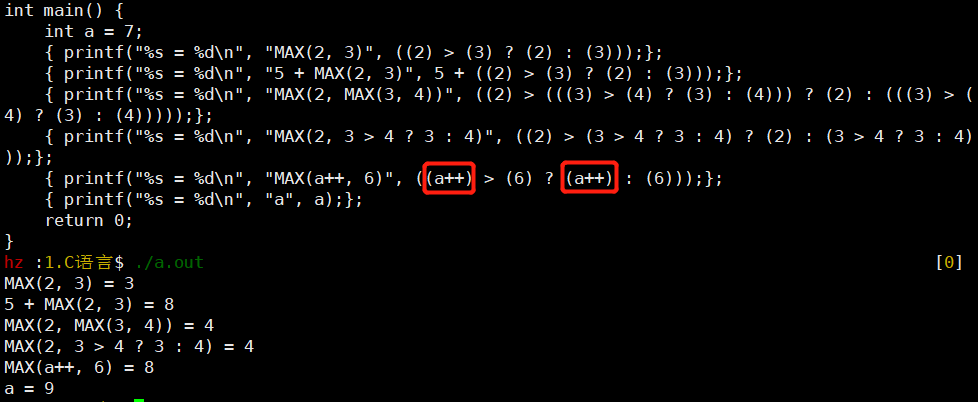
-
a++运行了两次
- 实际应该先拿a作比较,再进行a+1
-
解决:把++运算前的值先赋给一个变量;定义成一个代码段生成的表达式
-
- 第三次纠错
#define MAX(a, b) ({\
__typeof(a) _a = (a);\
__typeof(b) _b = (b);\
_a > _b ? _a : _b;\
})
-
__typeof(a++)里的a++执行吗?
- 用于表达式的时候不执行,只是取出其类型
-
({})表达式
-
值为小括号内最后一个表达式的值,数据类型为最后一个表达式的数据类型
-
参考C语言的小括号和花括号结合使用&&复合语句-CSDN
-
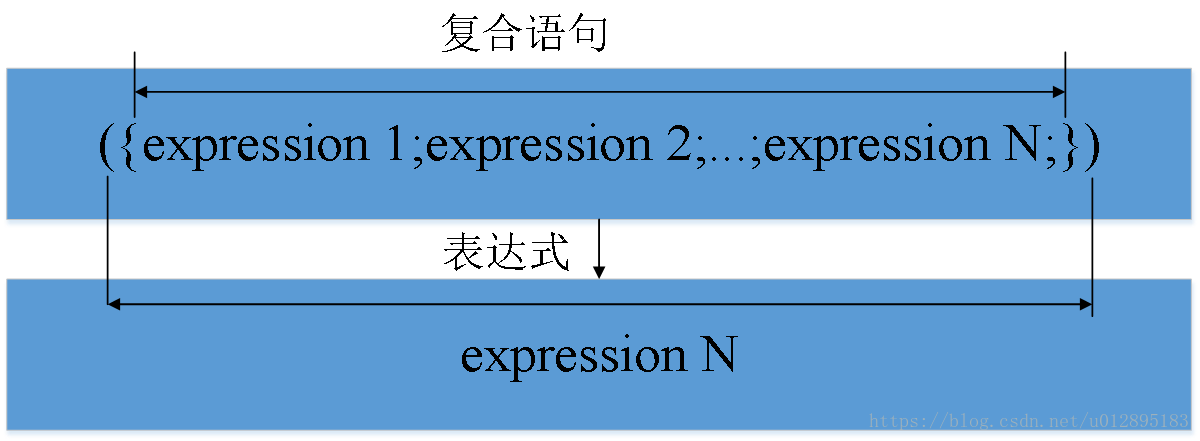
-
去掉{}或者()都不行!
- ()里只能放逗号表达式
- 逗号表达式取最后一个式子的值
- {}是代码段,没有返回值
- 若直接定义成宏函数
- 直接printf输出,就失去了MAX返回最大值的本质
- ❓用return返回值
- 需要声明
- 但直接用表达式代表返回值更聪明
- ()里只能放逗号表达式
-
-
最终版代码
-
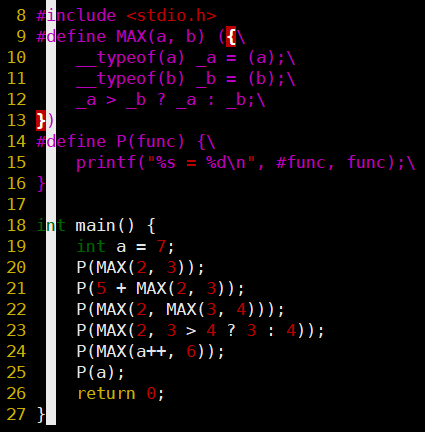
结果全部正确!
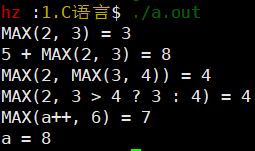
实现打印LOG宏
-

-

-
代码
-
-
交付工作时,免去log信息,可以使用条件式编译
- 编译时使用"gcc -DDEBUG"可以传入DEBUG宏定义
- #else后面定义一个空的宏替换
-
变参宏
- 变参'...'取一个名字即可。eg. args...
-
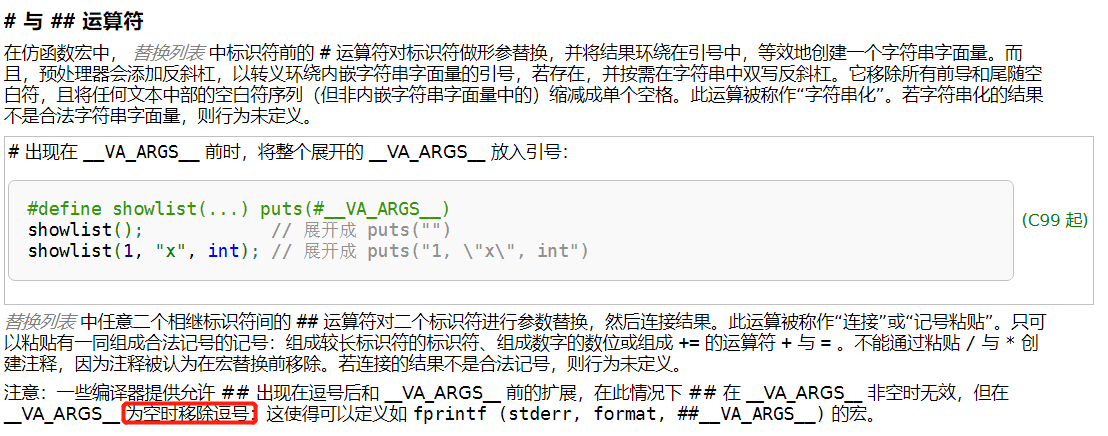
宏中 "#"、"##" 使用
- "#":取字符串
- "##":连接
-
解决log宏传入是空字符的情况:如果是空,frm后面的","会自动去除,可参考预编译结果👇
-
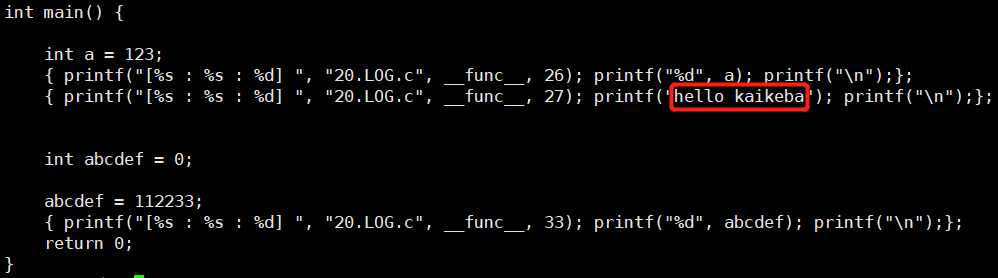
-
参考替换文本宏-cppreference
-
-
ab和a##b的区别
- ab不会将a、b代入再连接
- 需##连接的a、b对应的传入参数可以不定义
- 预处理就会将这些未定义的变量名连接起来,连接后的变量名定义过即可
-
-
亮点笔记
代码演示
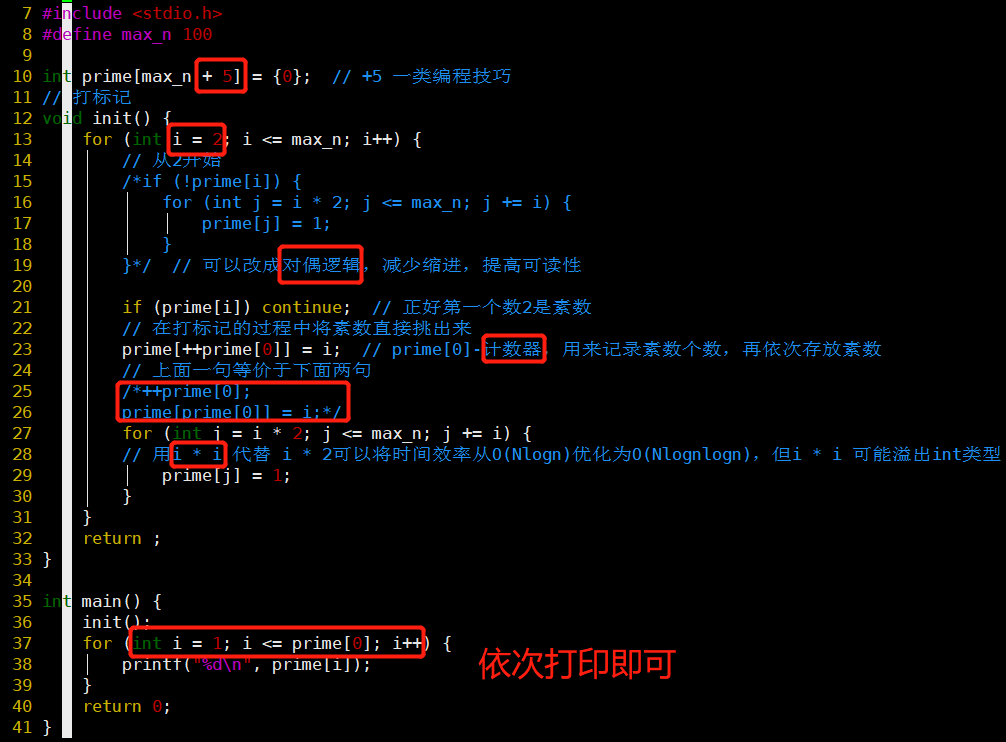
素数筛
代码
-
-
对偶逻辑,控制缩进
- if continue
-
prime数组前部分可以同时计数和存储(整体用来打标记)
- 一开始prime[0]、prime[1]并没有用,空闲着
- 不会出现超车的问题:偶数肯定是合数,素数至少隔一个才出现
-
第二个for循环的初始条件可以优化
- 初始条件:i * 2 → i * i
- 时间效率:O(Nlogn)→O(Nlognlogn)
- 因为比i * i小的合数肯定已经被比i小的数标记过了
- 这样减少了前面一部分重复标记的次数,但不是完全
- 完全避免重复标记要使用线性筛
- 危险点:i * i 指数增长,更可能溢出int能存储的最大值
- 是否可以提前加一个判断?不过可能带来更大的耗时
- 换一个上限更高的存储 i * i 的数据类型
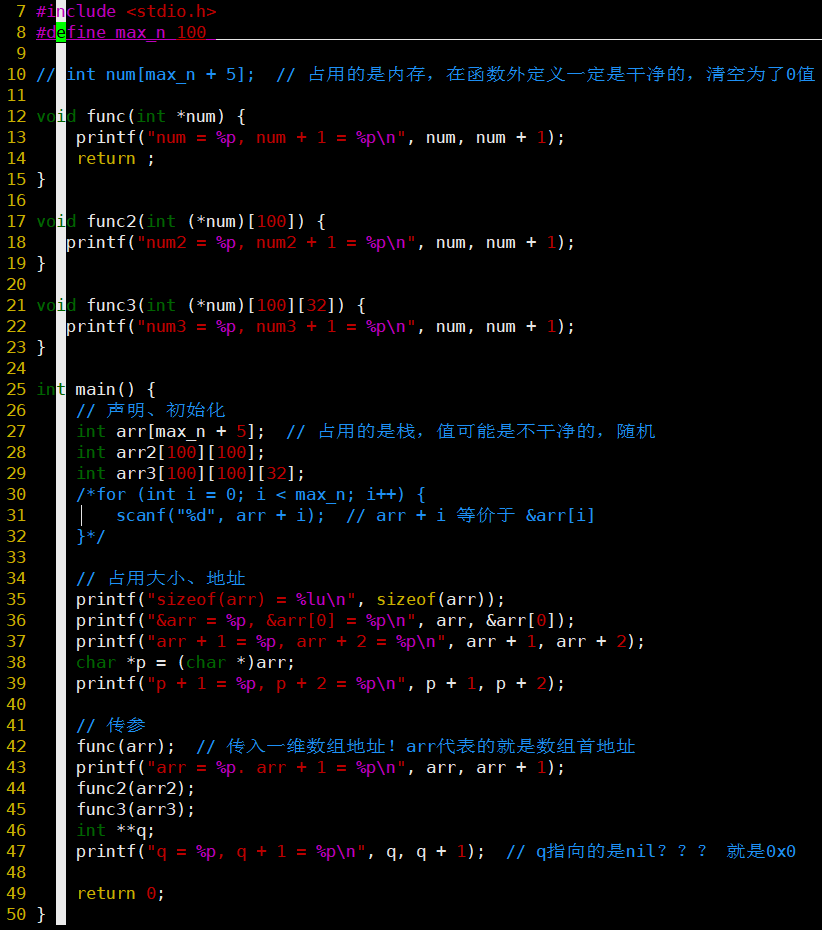
数组
代码
-
-
输出
-
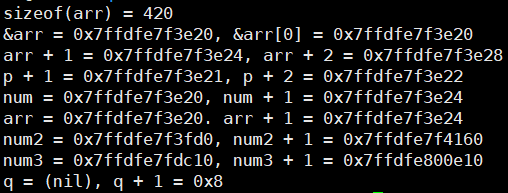
- 细节👇
-
声明、初始化
- 编程技巧:多开5位,避免溢出,可以降低bug率
#define max_n 100
int arr[max_n + 5];
- 在函数内的变量空间都定义在栈区
- 栈区可以用羽毛球筒去理解,后进先出
- 栈区大小(默认):8MB≈800万Byte(字节)
- 在函数内声明的数组可能是不干净的,需手动初始化
- = {0};
- scanf读入
for (int i = 0; i < max_n; i++) {
scanf("%d",arr + i);
}
-
- arr + i 等价于 &arr[i]&不能少!
- 在函数外声明的数组
- 系统会自动将其清空为0,类似于= {0}操作
- 可开辟大小受电脑内存限制,基本无限制
- malloc、calloc、realloc定义的数组在堆区,即使在函数内部定义
占用空间、地址
- sizeof()对应的控制字符是%lu,无符号长整型
- 数组名arr代表的就是数组的首地址,即&arr[0]
printf("%p %p\n", arr, &arr[0]); // 地址值一样
- 地址+1偏移多少字节取决于地址表示的元素字节数
传参
- 条件:外部和函数里参数表现形式一致
- 一维数组:int arr[100];
- void func(int *num)
- 二维数组:int arr2[100][100];
- void func2(int **num)报警告
- num + 1 和 arr + 1的表现形式不一致
- num是指向int指针的指针
- num和num +1的地址相差一个【指针】的大小,64位操作系统里是8个字节
- arr和arr + 1的地址相差一个【一维数组】的大小,4 * 100字节
- void func2(int (*num)[100]) 可以
- void func2(int **num)报警告
- 三维数组:int arr3[100][100][32]
- void func3(int (*num)[100][32]) 可以
- (*num)[100][32]可以写成num[][100][32]
- (*num)和num[]表现形式一样,但本质其实不一样
- 一维数组:int arr[100];
- ❓q指向的是nil?就是0x0
附加知识点
- 数组可以表示三种信息
- int arr[100]; // arr作为参数传到函数,是作为数组首元素的地址的
- 1取反是-2? 推导一下
- 1: 0000...001
- 取反:1111...110
- 符号位不变,取反加一得:1000...010
- 即-2
- 结论:所有正整数的按位取反是其本身+1的负数
- 包含<math.h>的源文件,在编译时添加-lm,使用gcc *.c -lm
- 编码习惯,一行不超过80个字符
- 控制字符"%X":大写的十六进制
思考点
- 函数与宏谁更厉害?
- 宏能生成函数,宏可不是函数的爸爸?
Tips
- vim自动补齐头文件的格式修改:加空格
- 进入~/.vimrc文件,修改SetTitle()里对应的格式即可
- 宏的展开、嵌套,自己去摸索
- 参考工具书第8章8.1、8.4以及第15章

